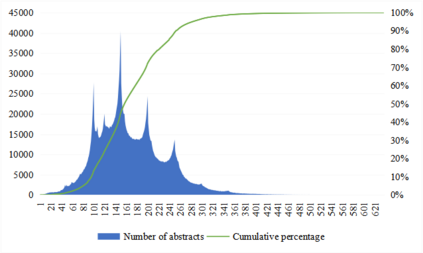
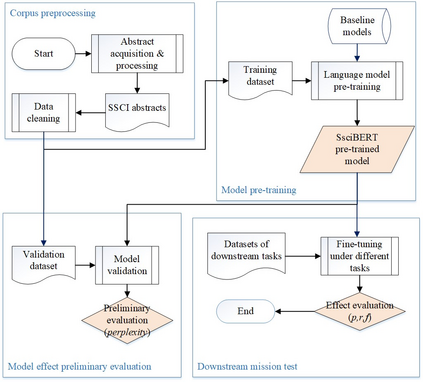
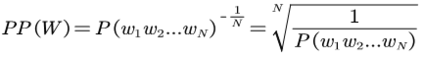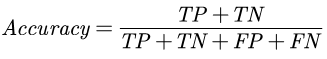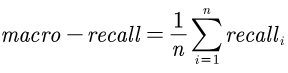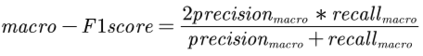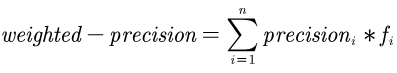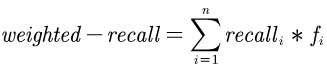The academic literature of social sciences is the literature that records human civilization and studies human social problems. With the large-scale growth of this literature, ways to quickly find existing research on relevant issues have become an urgent demand for researchers. Previous studies, such as SciBERT, have shown that pre-training using domain-specific texts can improve the performance of natural language processing tasks in those fields. However, there is no pre-trained language model for social sciences, so this paper proposes a pre-trained model on many abstracts published in the Social Science Citation Index (SSCI) journals. The models, which are available on Github (https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT), show excellent performance on discipline classification and abstract structure-function recognition tasks with the social sciences literature.
翻译:社会科学的学术文献是记录人类文明和研究人类社会问题的文献,随着这些文献的大规模发展,迅速找到关于相关问题的现有研究的方法已成为研究人员的迫切需求。以前的研究,如SciBERT, 已经表明,使用特定领域的文本进行预先培训可以改善这些领域自然语言处理任务的绩效。然而,社会科学没有经过预先培训的语言模式,因此本文件建议了社会科学引用指数杂志上公布的许多摘要的预先培训模式。Github(https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT)上的模型展示了在学科分类和社会科学文献的抽象结构功能识别任务方面的出色表现。