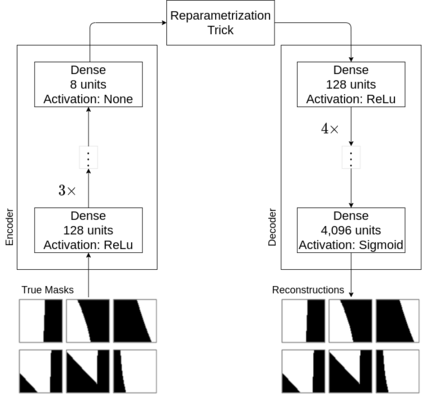
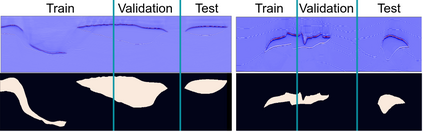
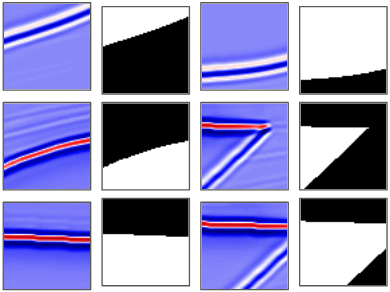
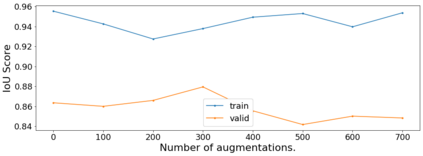
Nowadays, subsurface salt body localization and delineation, also called semantic segmentation of salt bodies, are among the most challenging geophysicist tasks. Thus, identifying large salt bodies is notoriously tricky and is crucial for identifying hydrocarbon reservoirs and drill path planning. This work proposes a Data Augmentation method based on training two generative models to augment the number of samples in a seismic image dataset for the semantic segmentation of salt bodies. Our method uses deep learning models to generate pairs of seismic image patches and their respective salt masks for the Data Augmentation. The first model is a Variational Autoencoder and is responsible for generating patches of salt body masks. The second is a Conditional Normalizing Flow model, which receives the generated masks as inputs and generates the associated seismic image patches. We evaluate the proposed method by comparing the performance of ten distinct state-of-the-art models for semantic segmentation, trained with and without the generated augmentations, in a dataset from two synthetic seismic images. The proposed methodology yields an average improvement of 8.57% in the IoU metric across all compared models. The best result is achieved by a DeeplabV3+ model variant, which presents an IoU score of 95.17% when trained with our augmentations. Additionally, our proposal outperformed six selected data augmentation methods, and the most significant improvement in the comparison, of 9.77%, is achieved by composing our DA with augmentations from an elastic transformation. At last, we show that the proposed method is adaptable for a larger context size by achieving results comparable to the obtained on the smaller context size.
翻译:目前,表层下盐体的本地化和划界,也称为盐体的语义分解,是最具挑战性的地球物理学任务之一。因此,确定大盐体是臭名昭著的棘手问题,对于确定碳氢化合物储库和钻孔路径规划至关重要。这项工作提议了一种数据增强方法,其基础是培训两个基因化模型,以增加盐体的语义分解地震图像数据集中的样本数量。我们的方法是利用深层学习模型生成地震图像补丁配对及其各自的盐面罩。第一个模型是挥发式自动coder,负责生成盐体面具补补丁。第二个模型是调整式循环模型,将生成的遮罩作为投入接收,并生成相关的地震图像补丁。我们通过比较10个截然不同的语义化图谱化模型的性能来评估拟议方法,这些模型是经过培训的,在两个合成地震放大图层图像集中生成的增益。第一个模型是8.57%的IO值衡量标准值, 与经过培训的10个直径化模型相比, 最佳结果是经过我们所选的直径化的直径化的直径分析结果,通过我们所选的直径变的直径化的直径分析模型,通过一个比的直径化的直径化模型,通过一个比的直径化模型,我们所选的直判的直径化的直径化模型, 显示的比的直判的直判的直径校算结果是经过了一个比的直方的模型,我们的直径图。