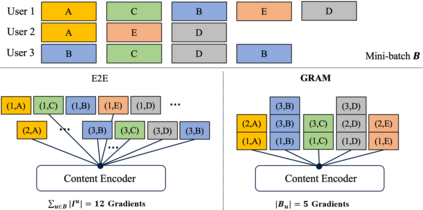
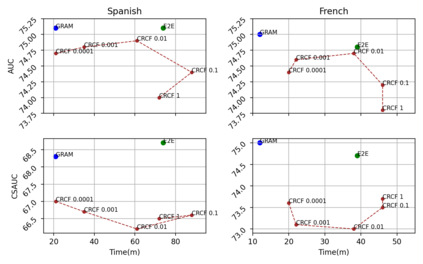
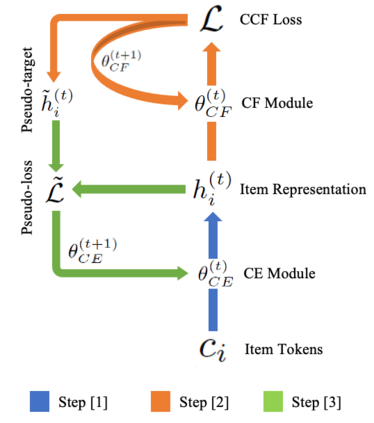
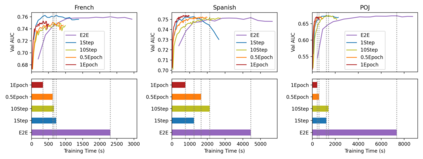
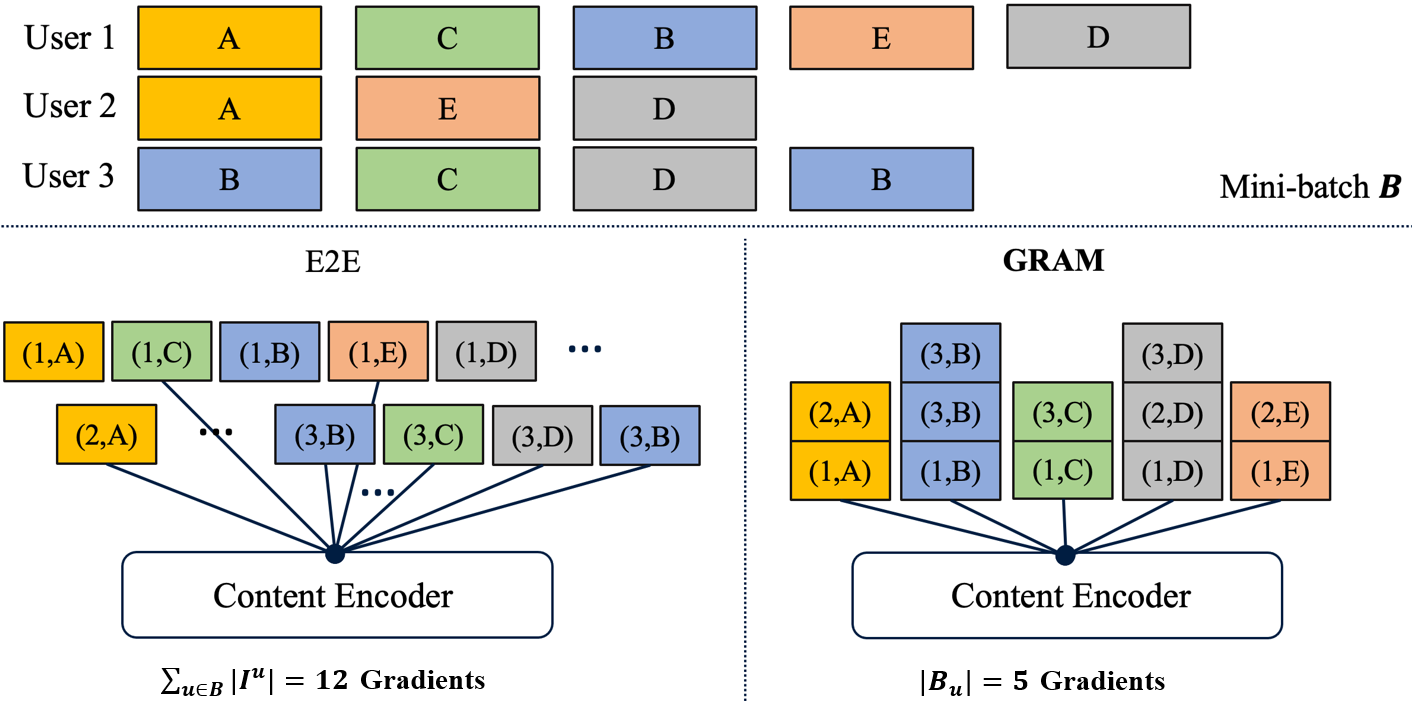
Content-based collaborative filtering (CCF) provides personalized item recommendations based on both users' interaction history and items' content information. Recently, pre-trained language models (PLM) have been used to extract high-quality item encodings for CCF. However, it is resource-intensive to finetune PLM in an end-to-end (E2E) manner in CCF due to its multi-modal nature: optimization involves redundant content encoding for interactions from users. For this, we propose GRAM (GRadient Accumulation for Multi-modality): (1) Single-step GRAM which aggregates gradients for each item while maintaining theoretical equivalence with E2E, and (2) Multi-step GRAM which further accumulates gradients across multiple training steps, with less than 40\% GPU memory footprint of E2E. We empirically confirm that GRAM achieves a remarkable boost in training efficiency based on five datasets from two task domains of Knowledge Tracing and News Recommendation, where single-step and multi-step GRAM achieve 4x and 45x training speedup on average, respectively.
翻译:基于内容的协作过滤(CCF)根据用户的互动历史和项目内容信息提供个性化项目建议。最近,使用预先培训的语言模型(PLM)为CCF提取高质量的项目编码。然而,由于CCF的多模式性质,以端到端方式微调PLM(E2E)需要大量资源:优化涉及用户互动的冗余内容编码。为此,我们提议GRAM(多式组合组合组合):(1)单步GRAM,将每个项目的梯度加在一起,同时保持与E2E的理论等同;(2)多步GRAM,在多个培训步骤中进一步积累梯度,而E2E的GPU记忆足迹不到40 ⁇ GPU。我们从经验上确认,GRAM在从知识追踪和新闻建议两个任务领域(即单步和多步GRAM平均达到4x和45x培训速度)的五个数据集的基础上,在培训效率上取得了显著的提高。