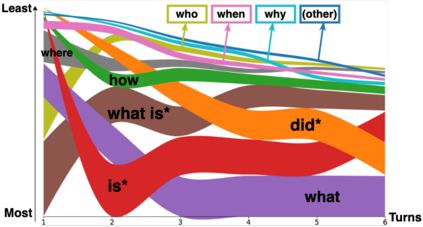
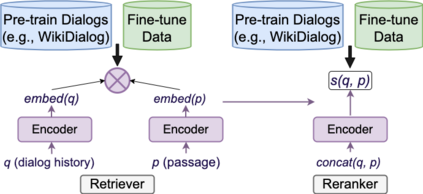
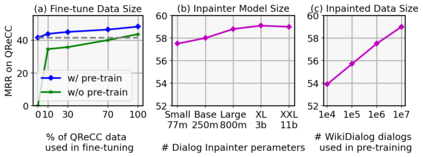
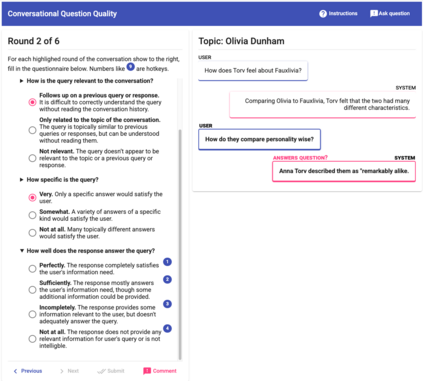
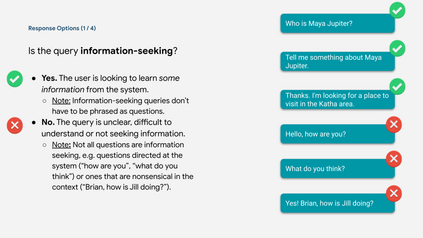
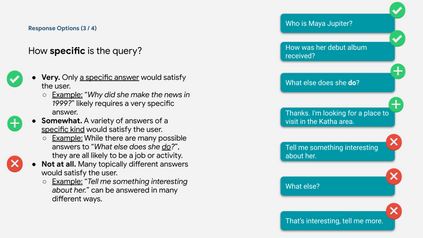
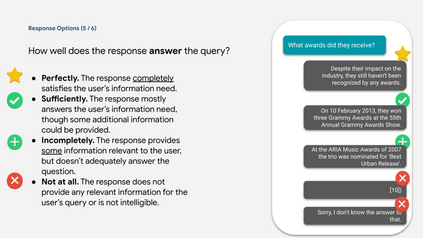
Many important questions (e.g. "How to eat healthier?") require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer's utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs -- 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
翻译:许多重要问题(例如“如何吃更健康? ” ) 需要对话才能建立背景和深入探讨。然而,对话问答(ConvQA)系统长期以来一直受到难以收集的培训数据(ConvQA)系统的干扰,因为收集的训练数据非常少。为了解决这一问题,我们提出了合成生成多样化和高质量对话数据的新技术:对话图画。我们的方法采纳了任何文件的文本,并将其转换成作者和想象中的读者之间的双人对话:我们把文章中的句子当作作者的发音处理,然后用对话来预测想象中的读者在作者的每个发音中要求或说的内容。我们通过对维基百科和网络的段落应用这一方法,产生了维基-迪亚洛格和WebDialog,两套数据集共1 900万个不同的信息查询对话,比现有的最大ConvQA数据集大1000x。此外,人类计算员们判断WikiDialog的答案是否足够和谈话性,好于现有的手动收集的40个相对数据库。我们用CARQ的进度前的数据检索系统。