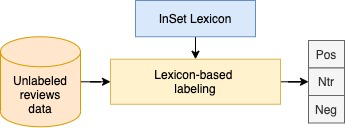
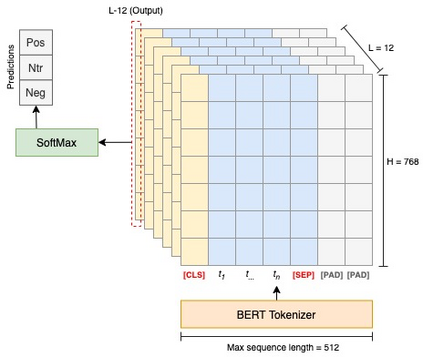
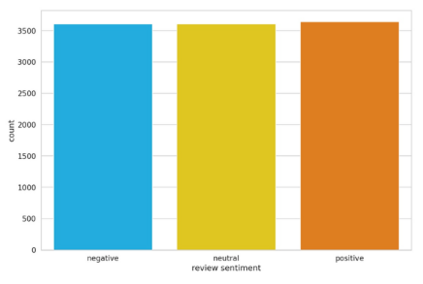
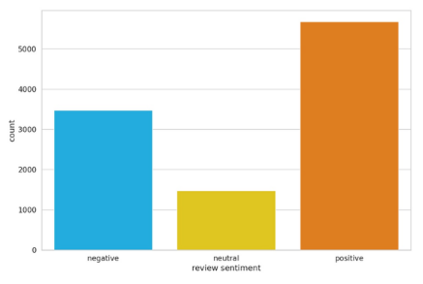
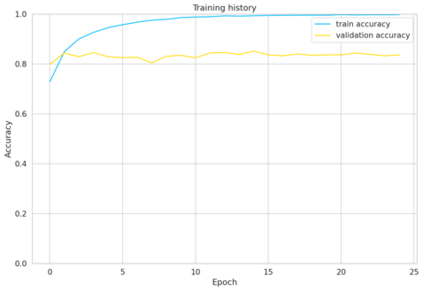
User reviews have an essential role in the success of the developed mobile apps. User reviews in the textual form are unstructured data, creating a very high complexity when processed for sentiment analysis. Previous approaches that have been used often ignore the context of reviews. In addition, the relatively small data makes the model overfitting. A new approach, BERT, has been introduced as a transfer learning model with a pre-trained model that has previously been trained to have a better context representation. This study examines the effectiveness of fine-tuning BERT for sentiment analysis using two different pre-trained models. Besides the multilingual pre-trained model, we use the pre-trained model that only has been trained in Indonesian. The dataset used is Indonesian user reviews of the ten best apps in 2020 in Google Play sites. We also perform hyper-parameter tuning to find the optimum trained model. Two training data labeling approaches were also tested to determine the effectiveness of the model, which is score-based and lexicon-based. The experimental results show that pre-trained models trained in Indonesian have better average accuracy on lexicon-based data. The pre-trained Indonesian model highest accuracy is 84%, with 25 epochs and a training time of 24 minutes. These results are better than all of the machine learning and multilingual pre-trained models.
翻译:用户审查在开发的移动应用程序的成功方面起着关键作用。 文本形式的用户审查是非结构化的数据,在处理情绪分析时产生了非常高的复杂程度。 以往采用的方法往往忽视审查的背景。 此外,相对较小的数据使模型过度使用。 此外,相对较小的数据使模型过度使用。 一种新的方法,即BERT, 已经作为转让学习模式引入,采用预先培训的模型,以前经过培训,以便有更好的背景代表。 本研究审查了微调BERT在使用两种不同的预培训模型进行情感分析方面的有效性。 除了多语言的预培训模型外,我们还使用仅用印度尼西亚语培训过的预培训模型。 所使用的数据集是印度尼西亚用户对2020年谷歌游戏网站的10个最佳应用程序的审查。 我们还进行了超参数调整,以找到最佳的经过培训的模型。 两种培训数据标签方法也经过测试,以确定模型的有效性,这种模型基于分数,以词汇为基础。 实验结果表明,在印度尼西亚培训的预培训模式在基于语言的数据上具有更好的平均准确性。 事先培训的印度尼西亚模型比基于语言的数据精确度要高84 % 和所有经过培训的机前学习的机程要更精确度。