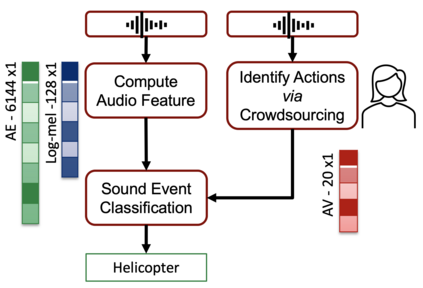
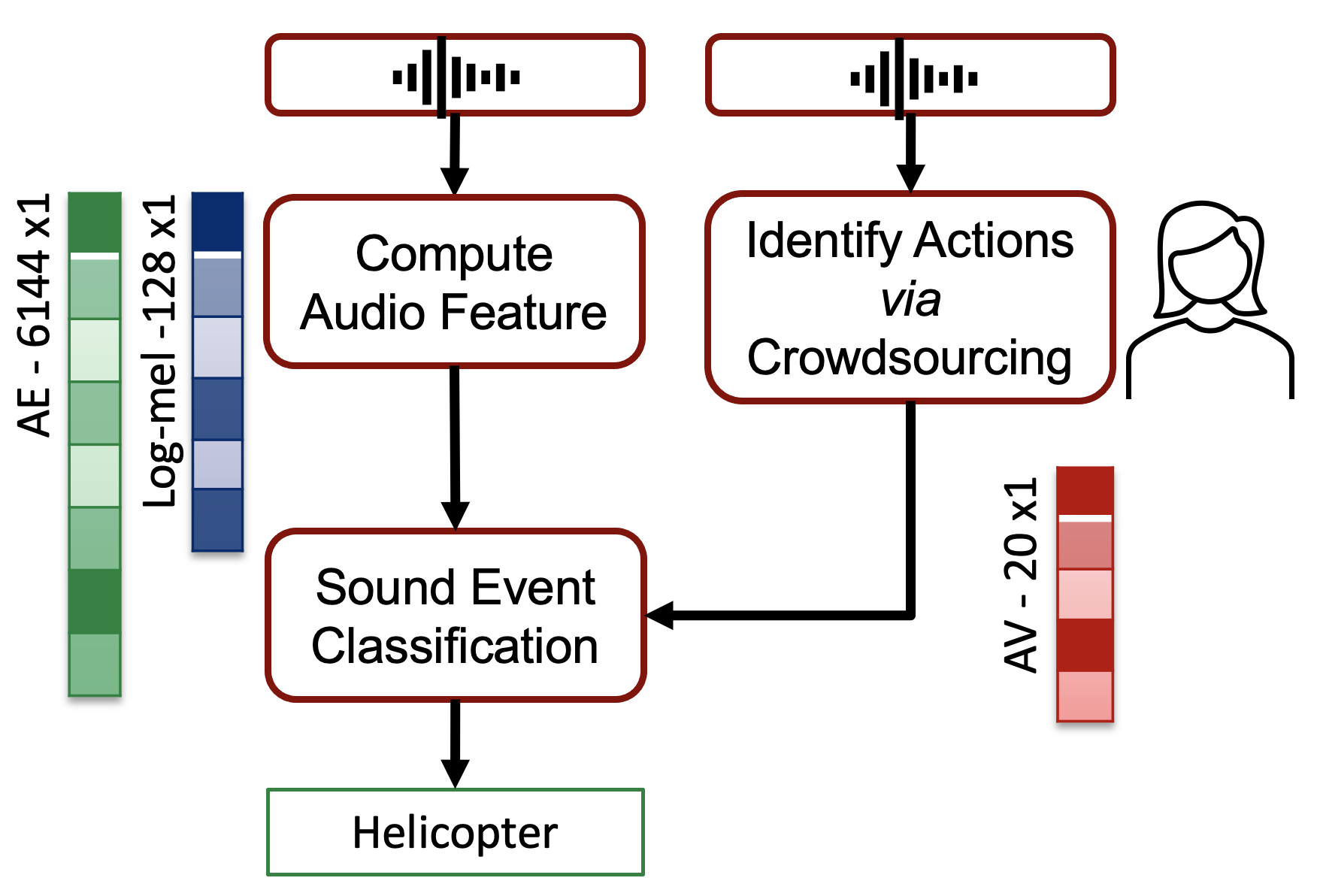
In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.
翻译:在心理学中,行动是人类感知和分离声音事件的首要因素。在机器学习(ML)中,行动识别达到高度准确性;然而,没有询问确定行动是否有利于健康事件分类(SEC),而不是将音频直接映射到一个声音事件。因此,我们为SEC提出一种新的具有心理学启发性的方法,其中包括通过人类听众识别行动。为实现这一目标,我们利用众包让听众识别20个单独或组合在研究周密的数据集ESC-50中可能产生50个声音事件的任何一个动作。由于音频特征和AV收集了声音内容的不同抽象性,我们把每个音频记录与第一个时间的音频事件数据库联系起来,在修订后将发布。这些说明被用来创建被称为“行动矢量”的语义表。我们通过将AV与两种类型的音频特征 -- -- log-mel 光谱和艺术音频嵌入状态 -- -- 比较来评价SEC。由于音频特征和AV收集了不同音频内容的抽象性,我们把它们合并起来,并在ESC-50最高级方法中展示了它们(86)改进了。