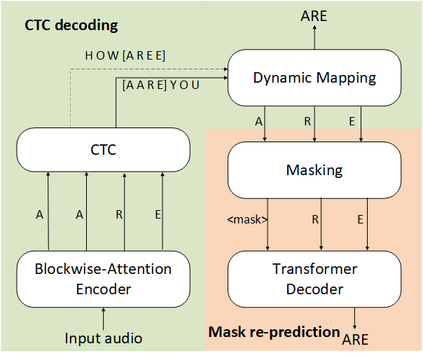
Non-autoregressive (NAR) modeling has gained more and more attention in speech processing. With recent state-of-the-art attention-based automatic speech recognition (ASR) structure, NAR can realize promising real-time factor (RTF) improvement with only small degradation of accuracy compared to the autoregressive (AR) models. However, the recognition inference needs to wait for the completion of a full speech utterance, which limits their applications on low latency scenarios. To address this issue, we propose a novel end-to-end streaming NAR speech recognition system by combining blockwise-attention and connectionist temporal classification with mask-predict (Mask-CTC) NAR. During inference, the input audio is separated into small blocks and then processed in a blockwise streaming way. To address the insertion and deletion error at the edge of the output of each block, we apply an overlapping decoding strategy with a dynamic mapping trick that can produce more coherent sentences. Experimental results show that the proposed method improves online ASR recognition in low latency conditions compared to vanilla Mask-CTC. Moreover, it can achieve a much faster inference speed compared to the AR attention-based models. All of our codes will be publicly available at https://github.com/espnet/espnet.
翻译:在语音处理中,非潜移(NAR)模型越来越受到越来越多的关注。在最近,最先进的关注型自动语音识别(ASR)结构中,NAR能够实现充满希望的实时因素(RTF)改善,而与自动递减模式相比,准确度仅小于小降。然而,这种识别推论需要等待完整语音发音的完成,这限制了其在低潜伏情景中的应用。为了解决这一问题,我们提议了一个新的端对端流语音识别系统,将阻断式注意和连接式时间分类与遮罩定位(Mask-CTC)NAR相结合。在推断中,输入音频将分解成小块,然后以阻断式流方式处理。为了解决每个区产出边缘的插入和删除错误,我们应用了重复的解调策略,而动态绘图技巧可以产生更加一致的句子。实验结果显示,拟议的方法可以改进低悬浮性状态状态下对NAR语音识别的在线识别,而与VIRA-Mask/CT模型相比较。此外,可以将快速地将输入我们的ARmasma-comnet模型。