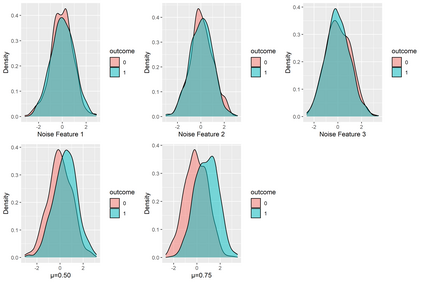
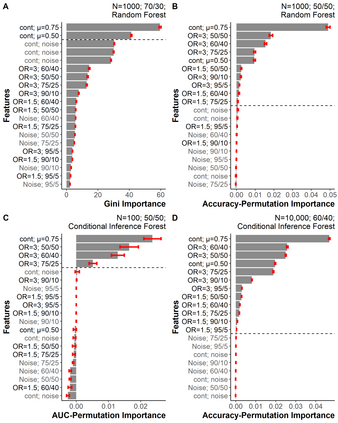
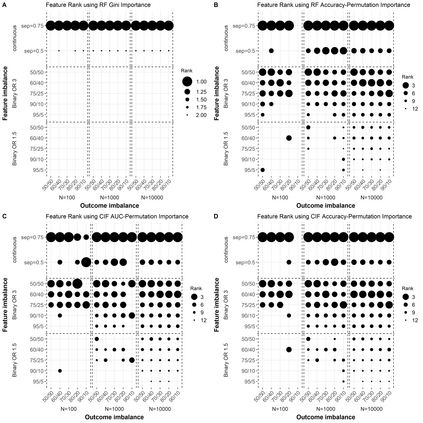
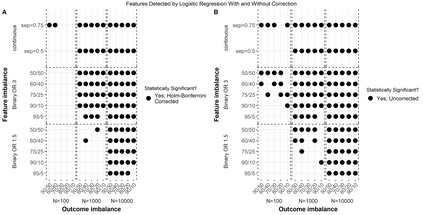
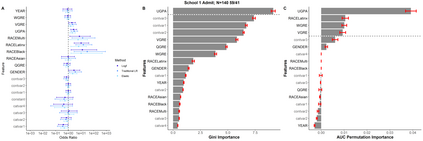
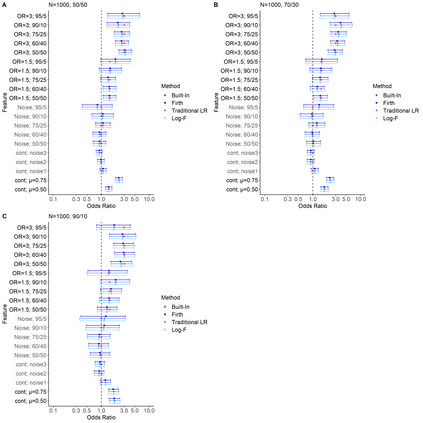
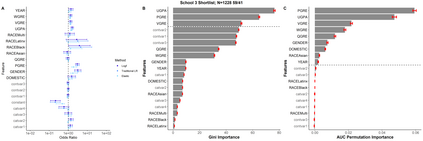
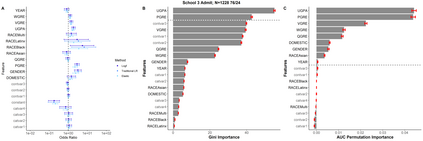
We encounter variables with little variation often in educational data mining (EDM) due to the demographics of higher education and the questions we ask. Yet, little work has examined how to analyze such data. Therefore, we conducted a simulation study using logistic regression, penalized regression, and random forest. We systematically varied the fraction of positive outcomes, feature imbalances, and odds ratios. We find the algorithms treat features with the same odds ratios differently based on the features' imbalance and the outcome imbalance. While none of the algorithms fully solved how to handle imbalanced data, penalized approaches such as Firth and Log-F reduced the difference between the built-in odds ratio and value determined by the algorithm. Our results suggest that EDM studies might contain false negatives when determining which variables are related to an outcome. We then apply our findings to a graduate admissions data set. We end by proposing recommendations that researchers should consider penalized regression for data sets on the order of hundreds of cases and should include more context about their data in publications such as the outcome and feature imbalances.
翻译:由于高等教育的人口统计和我们提出的问题,我们在教育数据挖掘(EDM)中经常遇到变化很少的变量。然而,几乎没有研究如何分析这些数据。因此,我们利用后勤回归、抑制回归和随机森林进行了模拟研究。我们系统地区分了正结果的分数、特征失衡和差数比率。我们发现算法根据特征的不平衡和结果不平衡,对相同差数比率的特征处理不同。虽然没有一个算法完全解决了如何处理不平衡数据的问题,但Firth和Log-F等惩罚性方法减少了内在误差比率和算法确定的价值之间的差别。我们的结果表明,EDM研究在确定与结果有关的变量时可能含有虚假的负差。我们然后将研究结果应用于研究生入学数据集。我们最后提出建议,研究人员应考虑根据数百个案例的顺序对数据集进行惩罚性回归,并在出版物中包括结果和特征失衡等关于其数据的更多背景。