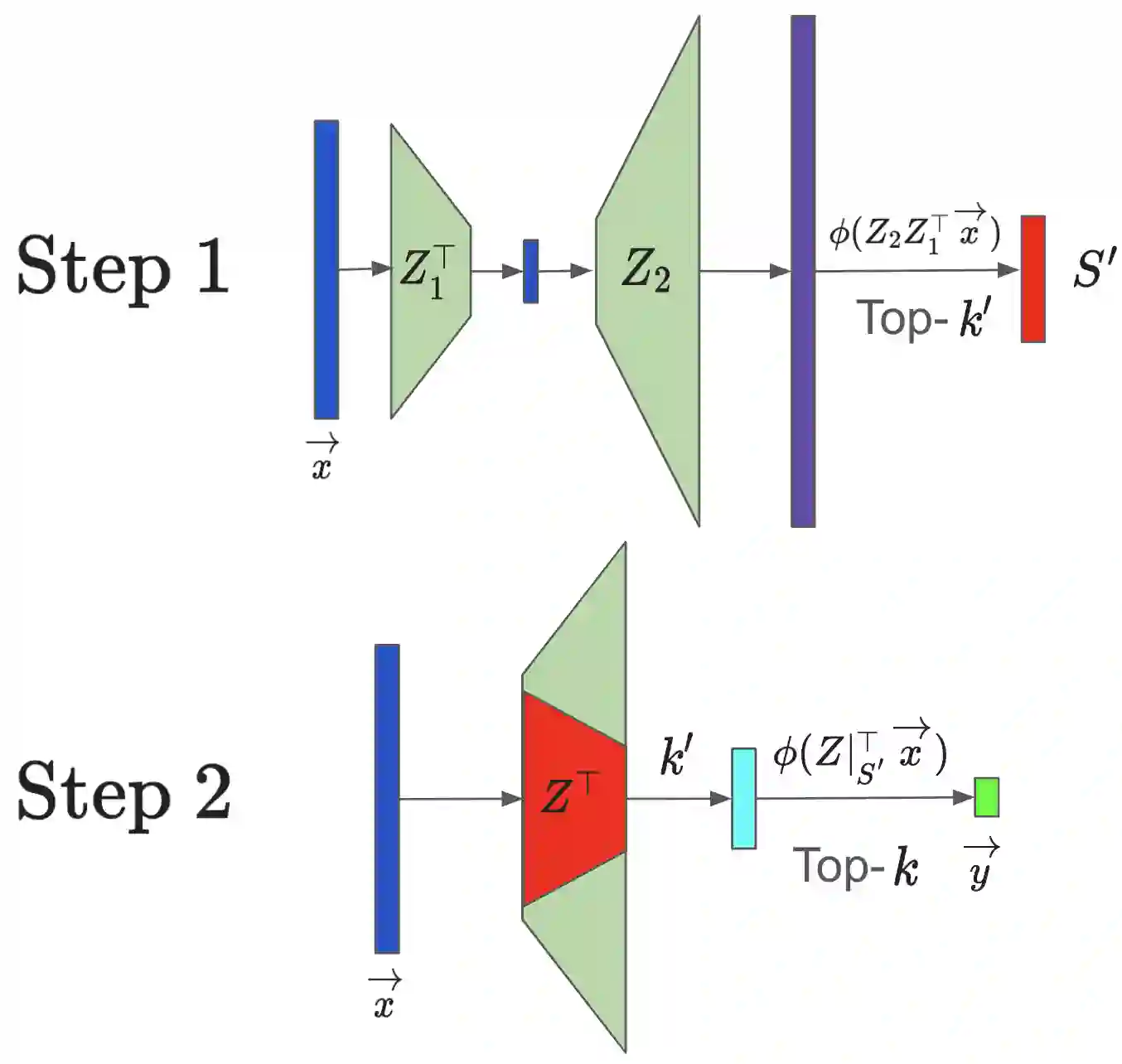
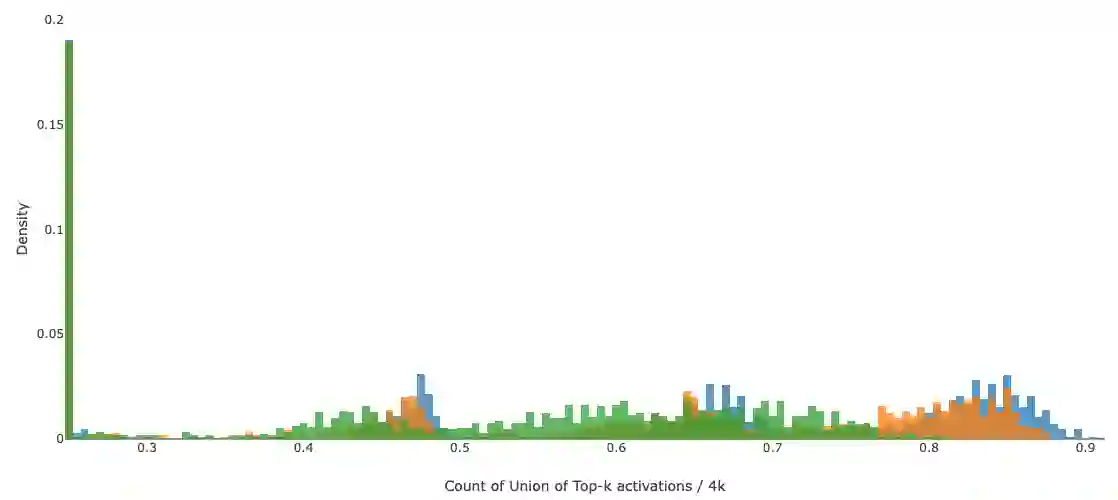
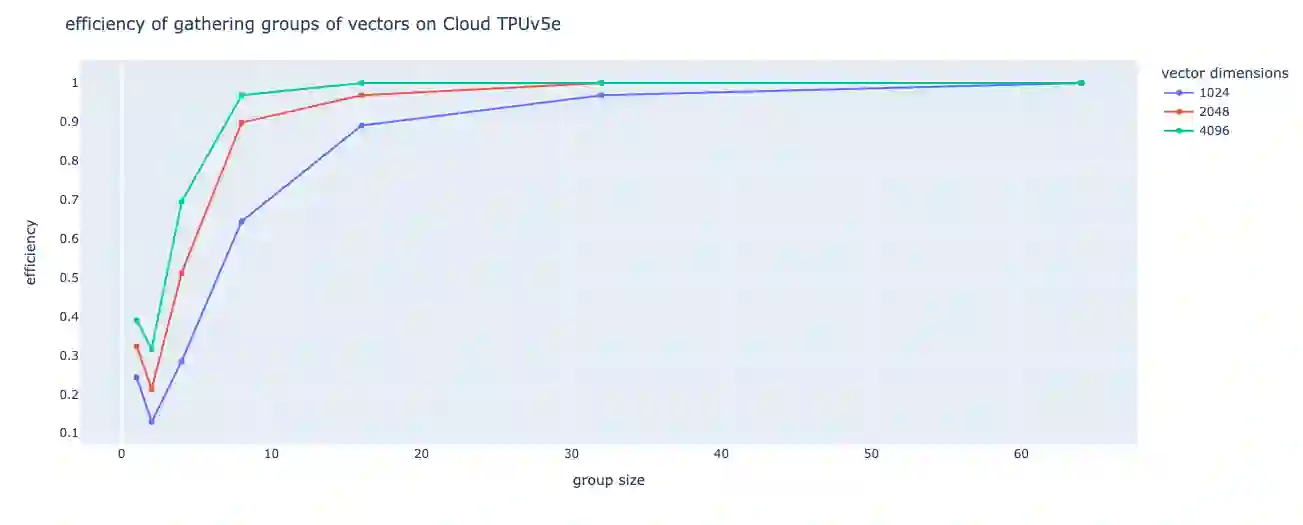
Autoregressive decoding with generative Large Language Models (LLMs) on accelerators (GPUs/TPUs) is often memory-bound where most of the time is spent on transferring model parameters from high bandwidth memory (HBM) to cache. On the other hand, recent works show that LLMs can maintain quality with significant sparsity/redundancy in the feedforward (FFN) layers by appropriately training the model to operate on a top-$k$ fraction of rows/columns (where $k \approx 0.05$), there by suggesting a way to reduce the transfer of model parameters, and hence latency. However, exploiting this sparsity for improving latency is hindered by the fact that identifying top rows/columns is data-dependent and is usually performed using full matrix operations, severely limiting potential gains. To address these issues, we introduce HiRE (High Recall Approximate Top-k Estimation). HiRE comprises of two novel components: (i) a compression scheme to cheaply predict top-$k$ rows/columns with high recall, followed by full computation restricted to the predicted subset, and (ii) DA-TOP-$k$: an efficient multi-device approximate top-$k$ operator. We demonstrate that on a one billion parameter model, HiRE applied to both the softmax as well as feedforward layers, achieves almost matching pretraining and downstream accuracy, and speeds up inference latency by $1.47\times$ on a single TPUv5e device.
翻译:暂无翻译