
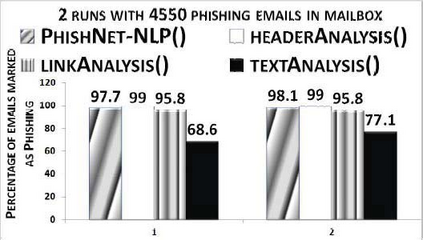
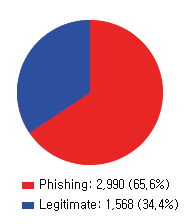
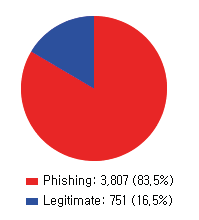
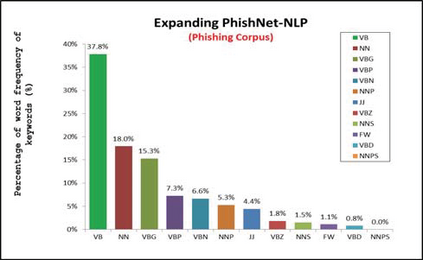
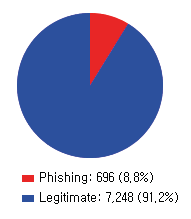
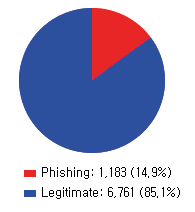
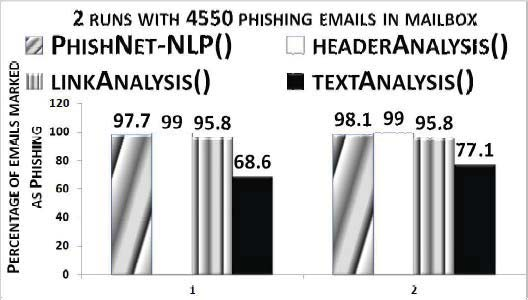
This paper reports on an experiment into text-based phishing detection using readily available resources and without the use of semantics. The developed algorithm is a modified version of previously published work that works with the same tools. The results obtained in recognizing phishing emails are considerably better than the previously reported work; but the rate of text falsely identified as phishing is slightly worse. It is expected that adding semantic component will reduce the false positive rate while preserving the detection accuracy.
翻译:本文报告利用现成的资源,在不使用语义学的情况下,对基于文字的钓鱼检测进行实验。开发的算法是以前出版的、使用相同工具的工作的修改版本。识别钓鱼邮件的结果比先前报告的工作好得多;但被错误识别为钓鱼的文字速度略微差一点。预计添加语义成分将降低假正率,同时保持探测的准确性。


相关内容

Arxiv
6+阅读 · 2018年3月27日
Arxiv
9+阅读 · 2018年3月13日

相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月27日
Arxiv
9+阅读 · 2018年3月13日