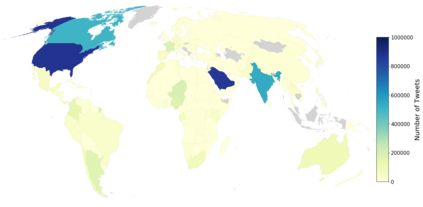
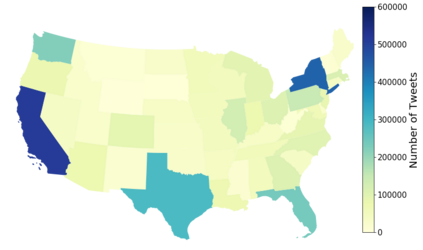
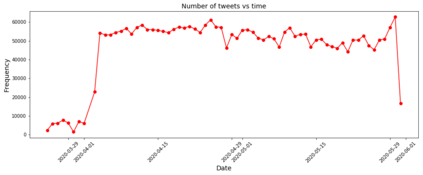
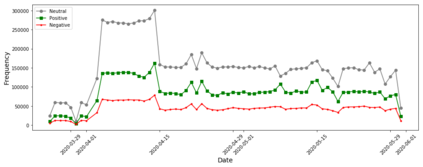
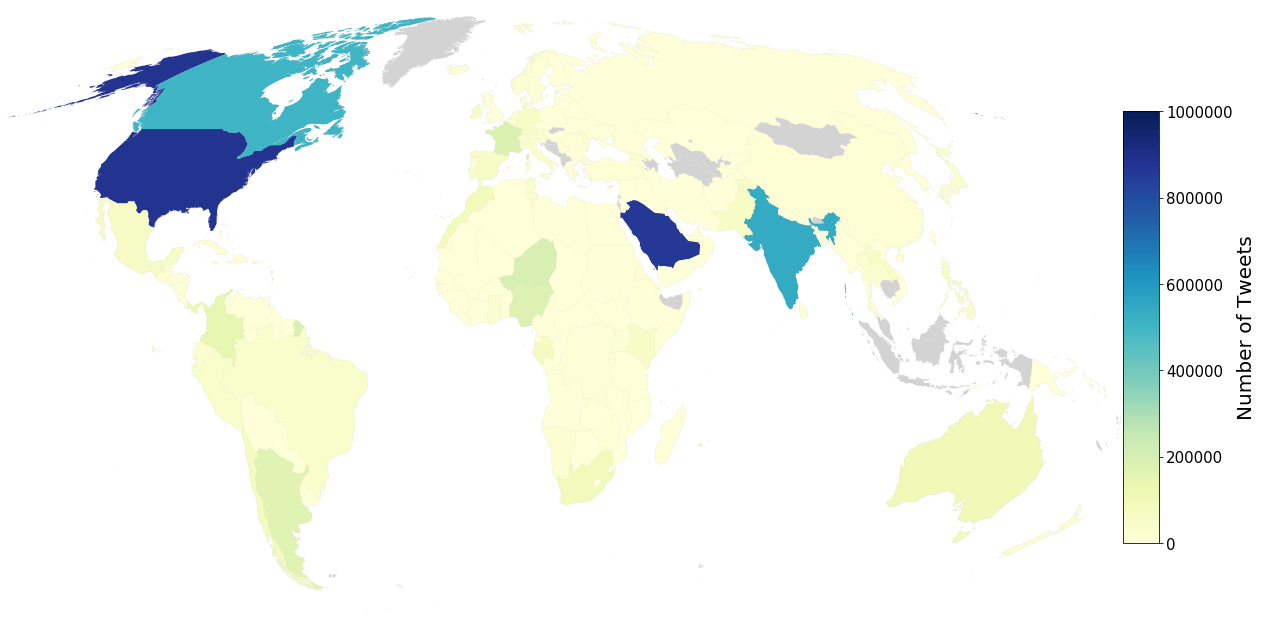
As a platform, Twitter has been a significant public space for discussion related to the COVID-19 pandemic. Public social media platforms such as Twitter represent important sites of engagement regarding the pandemic and these data can be used by research teams for social, health, and other research. Understanding public opinion about COVID-19 and how information diffuses in social media is important for governments and research institutions. Twitter is a ubiquitous public platform and, as such, has tremendous utility for understanding public perceptions, behavior, and attitudes related to COVID-19. In this research, we present CML-COVID, a COVID-19 Twitter data set of 19,298,967 million tweets from 5,977,653 unique individuals and summarize some of the attributes of these data. These tweets were collected between March 2020 and July 2020 using the query terms coronavirus, covid and mask related to COVID-19. We use topic modeling, sentiment analysis, and descriptive statistics to describe the tweets related to COVID-19 we collected and the geographical location of tweets, where available. We provide information on how to access our tweet dataset (archived using twarc).
翻译:作为平台,Twitter是讨论与COVID-19大流行有关的公共空间,Twitter等公共社交媒体平台代表了有关该流行病的重要接触网站,这些数据可供研究小组用于社会、卫生和其他研究。了解关于COVID-19的公众舆论,以及社交媒体信息传播对政府和研究机构的重要性。Twitter是一个无处不在的公共平台,因此对了解与COVID-19有关的公众认识、行为和态度有很大的用处。在这项研究中,我们介绍了CML-COVID-19的一组数据,即来自5 977 653个独特个人的19 298 967万个Twitter数据集,并总结了这些数据的一些属性。这些推特是在2020年3月至2020年7月使用与COVID-19有关的 Corona病毒、covid和面具等查询术语收集的。我们使用主题模型、情绪分析和描述我们收集的与COVID-19有关的推文的推文和可获取的地理位置。我们提供了关于如何获取我们推特数据的信息(使用twarcs)。