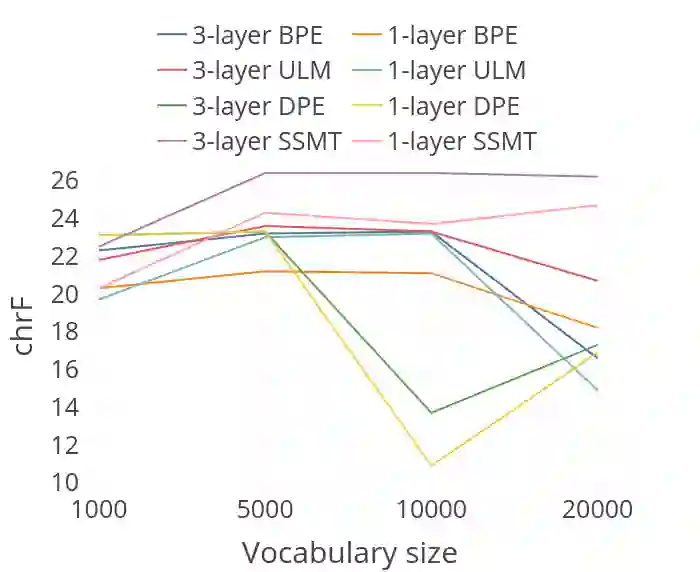
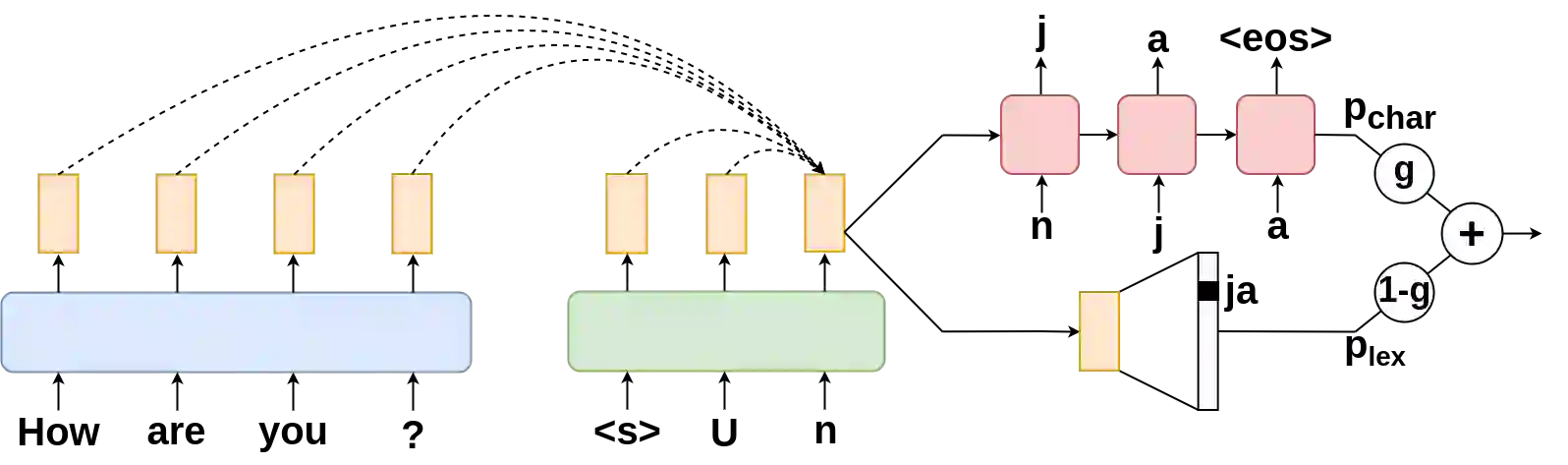Subword segmenters like BPE operate as a preprocessing step in neural machine translation and other (conditional) language models. They are applied to datasets before training, so translation or text generation quality relies on the quality of segmentations. We propose a departure from this paradigm, called subword segmental machine translation (SSMT). SSMT unifies subword segmentation and MT in a single trainable model. It learns to segment target sentence words while jointly learning to generate target sentences. To use SSMT during inference we propose dynamic decoding, a text generation algorithm that adapts segmentations as it generates translations. Experiments across 6 translation directions show that SSMT improves chrF scores for morphologically rich agglutinative languages. Gains are strongest in the very low-resource scenario. SSMT also learns subwords that are closer to morphemes compared to baselines and proves more robust on a test set constructed for evaluating morphological compositional generalisation.
翻译:暂无翻译