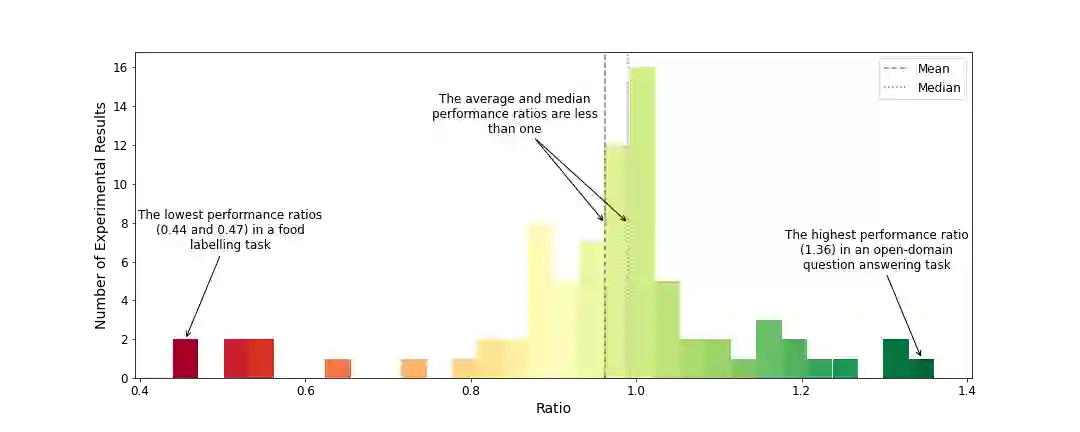
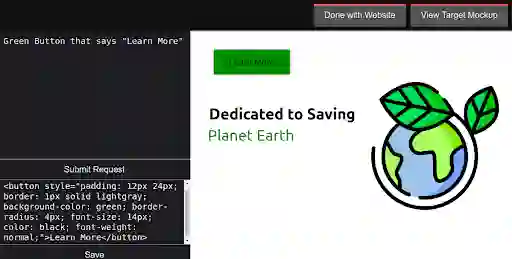
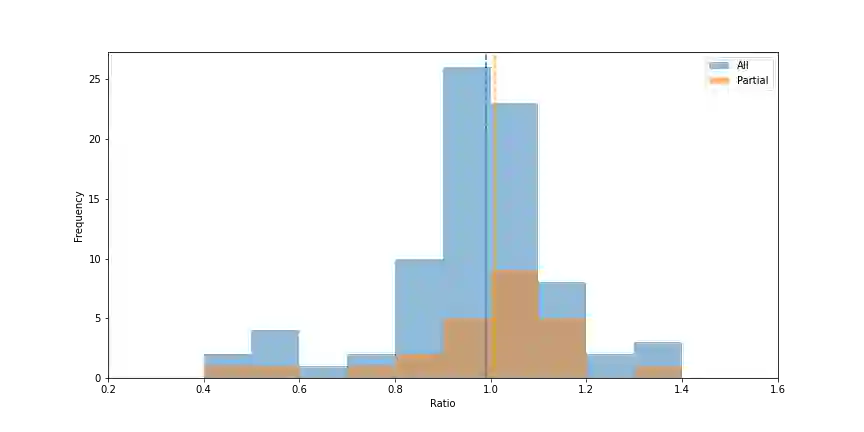
The Turing test for comparing computer performance to that of humans is well known, but, surprisingly, there is no widely used test for comparing how much better human-computer systems perform relative to humans alone, computers alone, or other baselines. Here, we show how to perform such a test using the ratio of means as a measure of effect size. Then we demonstrate the use of this test in three ways. First, in an analysis of 79 recently published experimental results, we find that, surprisingly, over half of the studies find a decrease in performance, the mean and median ratios of performance improvement are both approximately 1 (corresponding to no improvement at all), and the maximum ratio is 1.36 (a 36% improvement). Second, we experimentally investigate whether a higher performance improvement ratio is obtained when 100 human programmers generate software using GPT-3, a massive, state-of-the-art AI system. In this case, we find a speed improvement ratio of 1.27 (a 27% improvement). Finally, we find that 50 human non-programmers using GPT-3 can perform the task about as well as--and less expensively than--the human programmers. In this case, neither the non-programmers nor the computer would have been able to perform the task alone, so this is an example of a very strong form of human-computer synergy.
翻译:将计算机性能与人类性能进行比较的图灵测试是众所周知的,但令人惊讶的是,在比较人类性能与人类性能相比是否比单独、计算机或其它基线表现得更好方面没有广泛使用的测试。在这里,我们展示了如何使用手段比率作为衡量效果大小的尺度来进行这种测试。然后我们用三种方式展示了这一测试的使用情况。首先,在对最近公布的79项实验结果的分析中,我们发现,令人惊讶的是,一半以上的研究发现性能下降,业绩改进的平均和中位比率大约为1个(对完全没有改进的响应),而最高比率为1.36个(36%的改进)。第二,我们实验性能改进率是否在100个人类程序员使用GPT-3生成软件时得到更高水平的测试,这是一种大规模、最先进的人工智能系统。我们发现,速度改进率为1.27(27%的改进 ) 。最后,我们发现,使用GPT-3的50个非程序员既能完成这项任务,也比计算机型号要低得多,但光是无法执行的计算机。