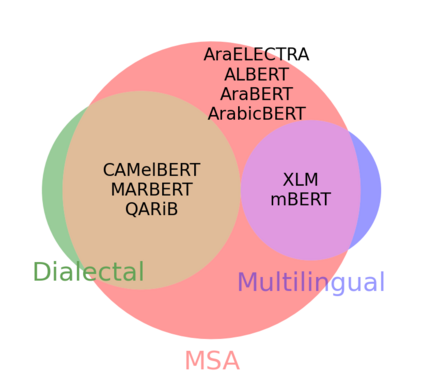
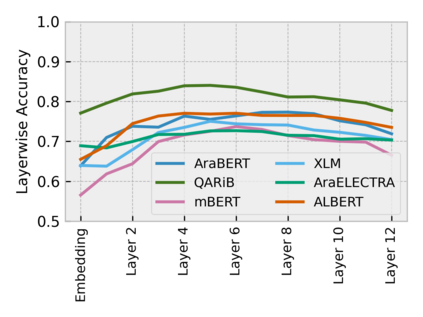
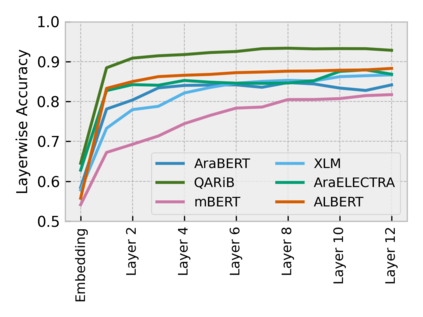
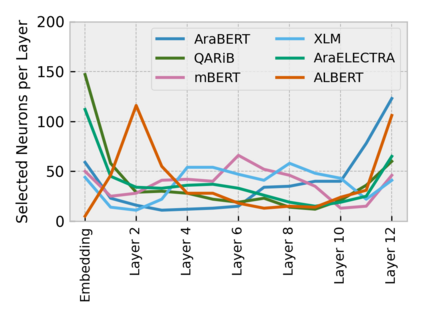
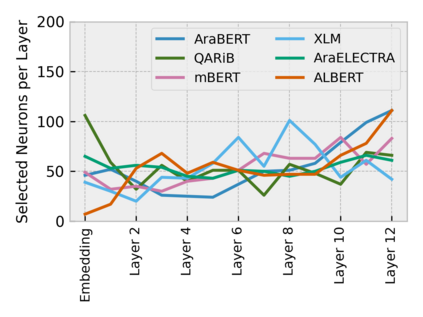
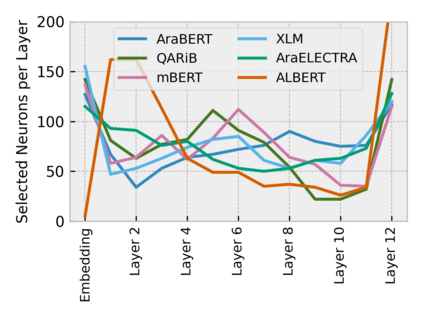
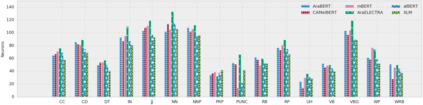
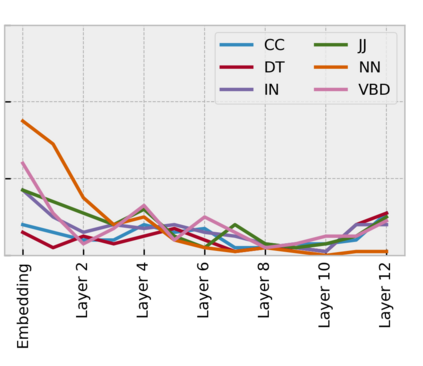
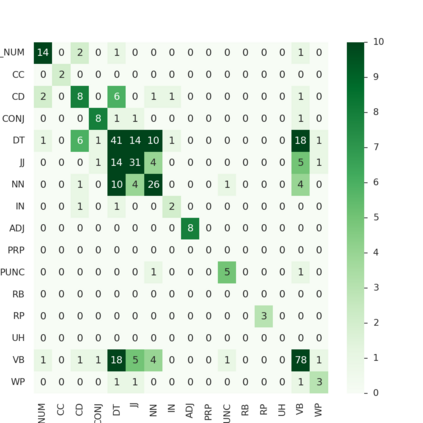
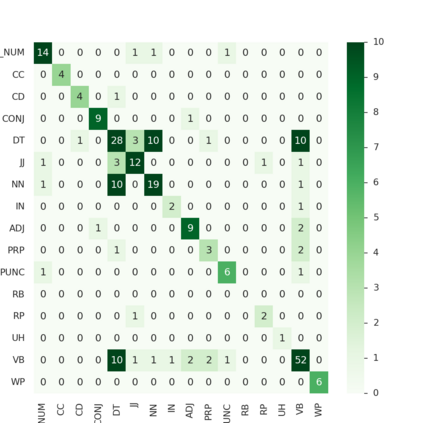
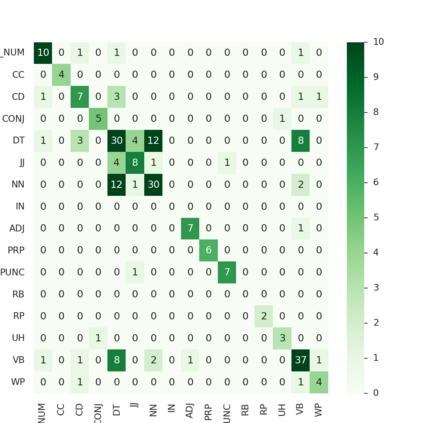
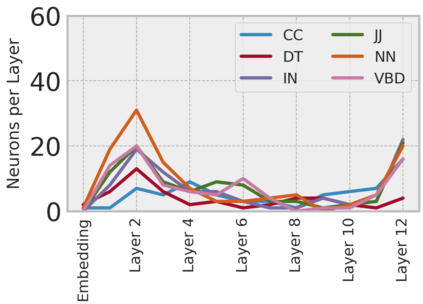
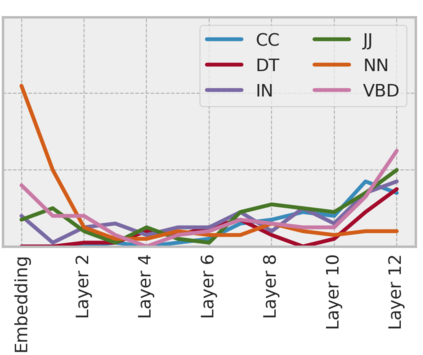
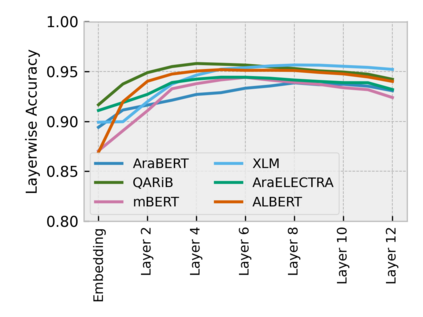
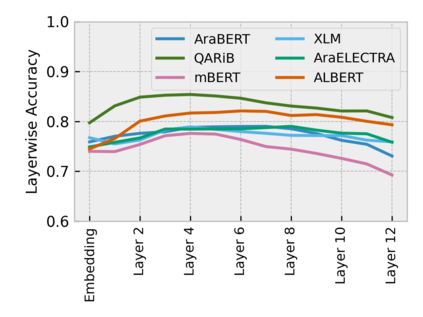
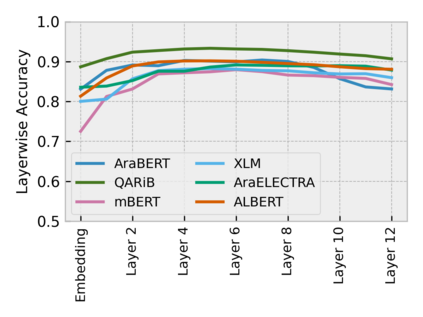
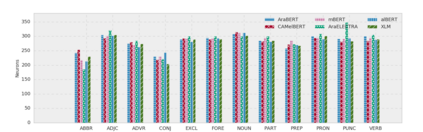
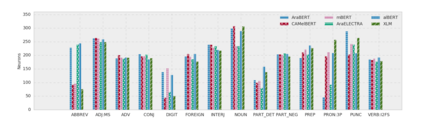
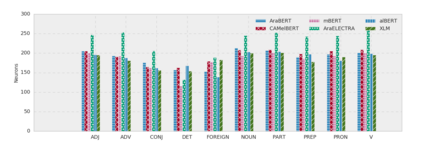
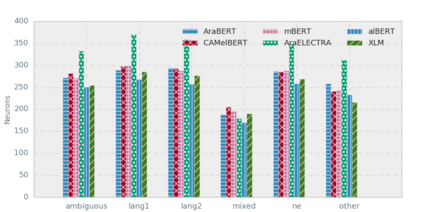
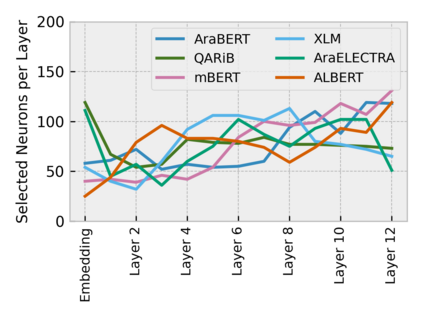
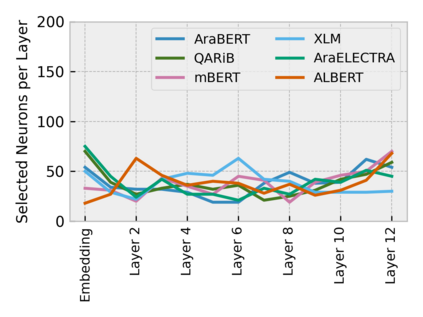
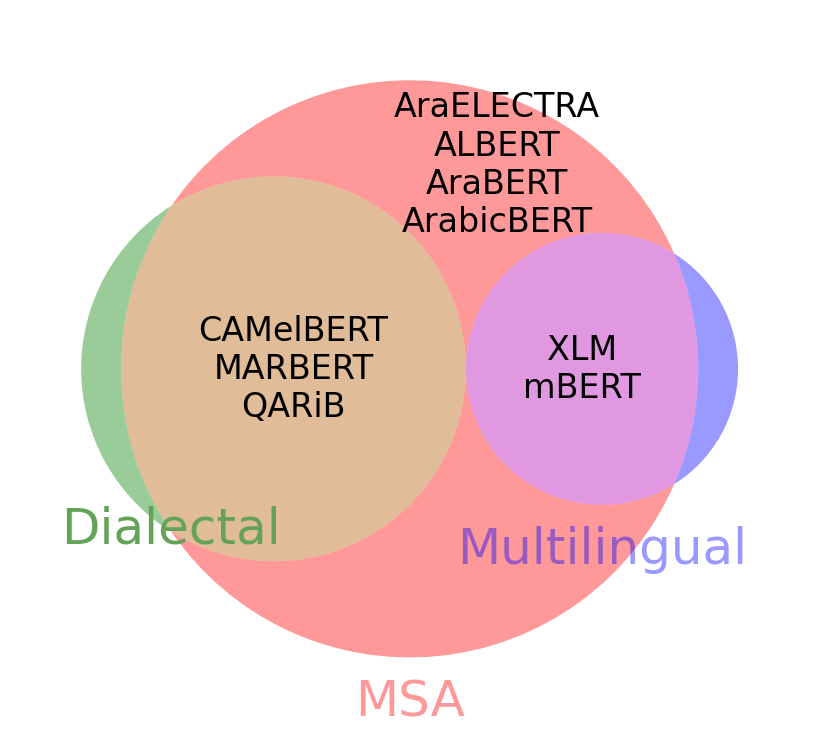
Arabic is a Semitic language which is widely spoken with many dialects. Given the success of pre-trained language models, many transformer models trained on Arabic and its dialects have surfaced. While there have been an extrinsic evaluation of these models with respect to downstream NLP tasks, no work has been carried out to analyze and compare their internal representations. We probe how linguistic information is encoded in the transformer models, trained on different Arabic dialects. We perform a layer and neuron analysis on the models using morphological tagging tasks for different dialects of Arabic and a dialectal identification task. Our analysis enlightens interesting findings such as: i) word morphology is learned at the lower and middle layers, ii) while syntactic dependencies are predominantly captured at the higher layers, iii) despite a large overlap in their vocabulary, the MSA-based models fail to capture the nuances of Arabic dialects, iv) we found that neurons in embedding layers are polysemous in nature, while the neurons in middle layers are exclusive to specific properties
翻译:阿拉伯语是一种犹太语言,许多方言都广泛使用。鉴于预先培训的语言模型的成功,许多经过阿拉伯语及其方言培训的变压器模型已经浮现出来。虽然对这些模型的下游国家语言方案任务进行了外部评估,但没有开展分析和比较内部表述的工作。我们探讨如何在变压器模型中编码语言信息,对不同的阿拉伯语方言进行了培训。我们利用不同阿拉伯语方言和方言识别任务的形态标记任务对模型进行层和神经元分析。我们的分析揭示了一些有趣的发现,例如:(一) 低层和中层都学了词型学,(二) 虽然合成依赖性主要在较高层中,(三) 尽管词汇中有很大的重叠,但基于特派任务生活津贴的模式未能捕捉到阿拉伯语方言的细微,(四) 我们发现,嵌入层中的神经是多元性的,而中层的神经是特定特性的专属性。