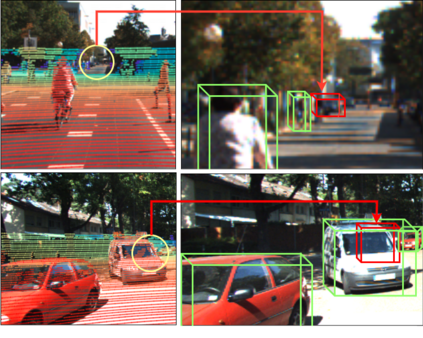
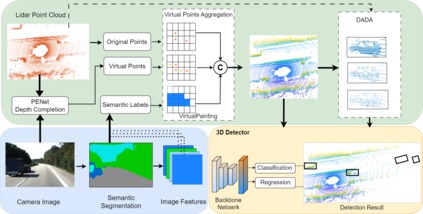
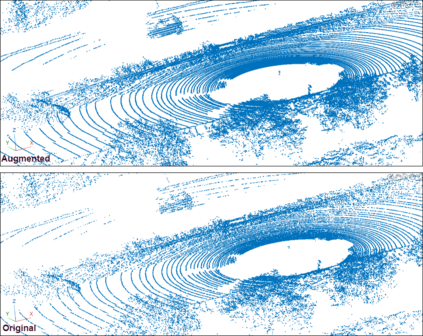
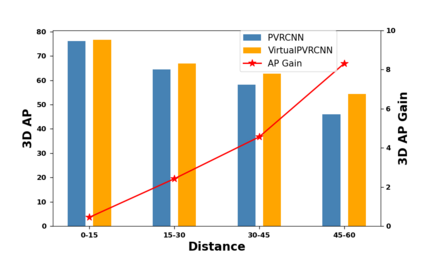
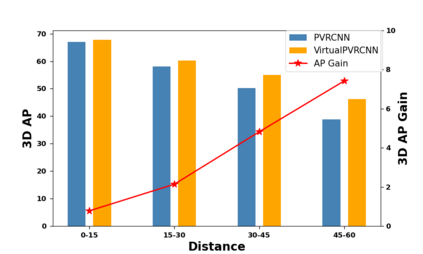
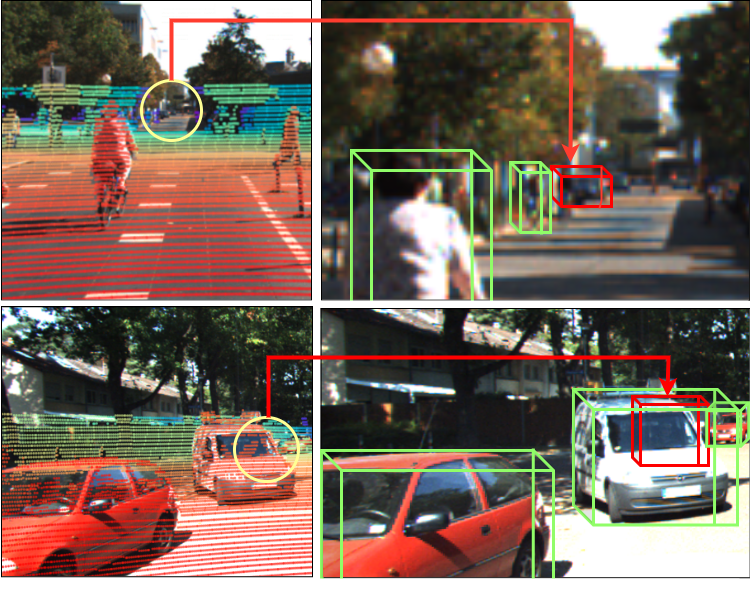
In recent times, there has been a notable surge in multimodal approaches that decorates raw LiDAR point clouds with camera-derived features to improve object detection performance. However, we found that these methods still grapple with the inherent sparsity of LiDAR point cloud data, primarily because fewer points are enriched with camera-derived features for sparsely distributed objects. We present an innovative approach that involves the generation of virtual LiDAR points using camera images and enhancing these virtual points with semantic labels obtained from image-based segmentation networks to tackle this issue and facilitate the detection of sparsely distributed objects, particularly those that are occluded or distant. Furthermore, we integrate a distance aware data augmentation (DADA) technique to enhance the models capability to recognize these sparsely distributed objects by generating specialized training samples. Our approach offers a versatile solution that can be seamlessly integrated into various 3D frameworks and 2D semantic segmentation methods, resulting in significantly improved overall detection accuracy. Evaluation on the KITTI and nuScenes datasets demonstrates substantial enhancements in both 3D and birds eye view (BEV) detection benchmarks
翻译:暂无翻译