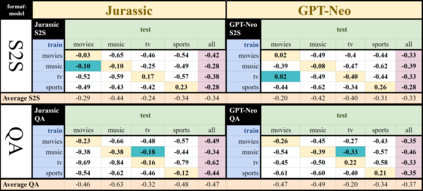
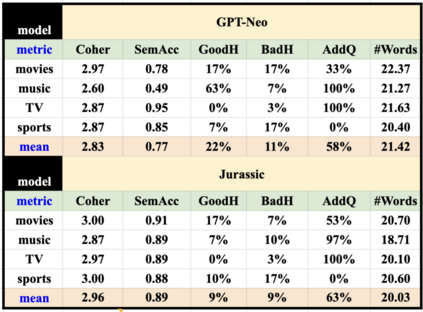
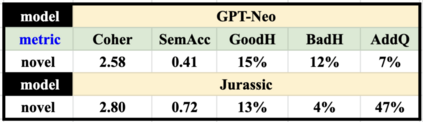
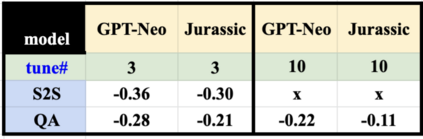
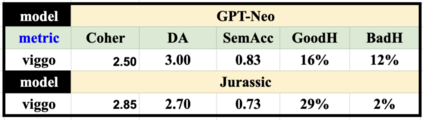
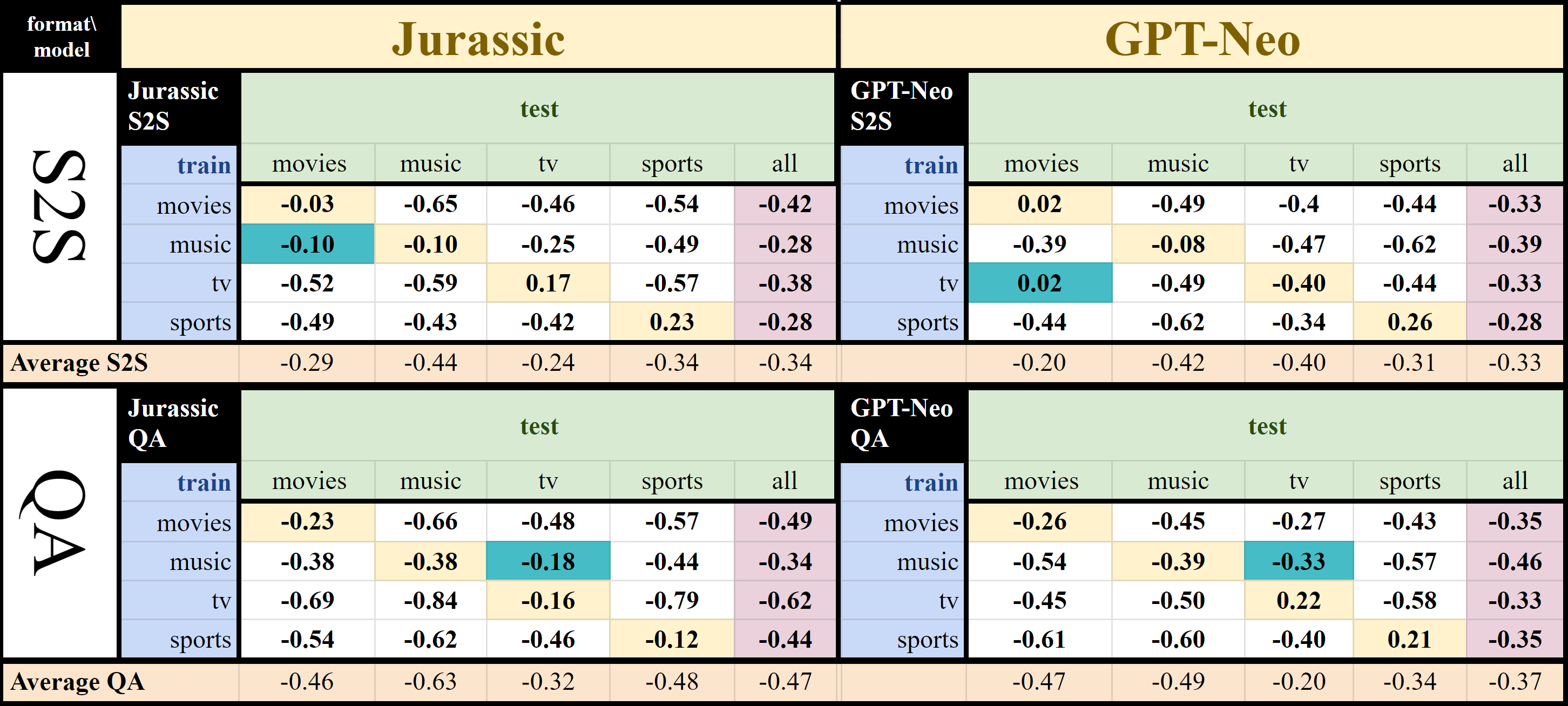
One challenge with open-domain dialogue systems is the need to produce high-quality responses on any topic. We aim to improve the quality and coverage of Athena, an Alexa Prize dialogue system. We utilize Athena's response generators (RGs) to create training data for two new neural Meaning-to-Text RGs, Athena-GPT-Neo and Athena-Jurassic, for the movies, music, TV, sports, and video game domains. We conduct few-shot experiments, both within and cross-domain, with different tuning set sizes (2, 3, 10), prompt formats, and meaning representations (MRs) for sets of WikiData KG triples, and dialogue acts with 14 possible attribute combinations. Our evaluation uses BLEURT and human evaluation metrics, and shows that with 10-shot tuning, Athena-Jurassic's performance is significantly better for coherence and semantic accuracy. Experiments with 2-shot tuning on completely novel MRs results in a huge performance drop for Athena-GPT-Neo, whose semantic accuracy falls to 0.41, and whose untrue hallucination rate increases to 12%. Experiments with dialogue acts for video games show that with 10-shot tuning, both models learn to control dialogue acts, but Athena-Jurassic has significantly higher coherence, and only 4% untrue hallucinations. Our results suggest that Athena-Jurassic can reliably produce outputs of high-quality for live systems with real users. To our knowledge, these are the first results demonstrating that few-shot tuning on a massive language model can create NLGs that generalize to new domains, and produce high-quality, semantically-controlled, conversational responses directly from MRs and KG triples.
翻译:开放域对话系统的一个挑战是需要就任何议题提出高质量的回应。 我们的目标是提高亚历克萨奖对话系统Athena的质量和覆盖面。 我们使用Athena的响应生成器(RGs)为两个新的神经感官至Text RGs、Athena-GPT-Neo和Athena-Jurassic为电影、音乐、电视、体育和视频游戏领域创建培训数据。 我们在内部和跨多域内都进行几发试验,其调试大小不同(2、3、10)、快速格式和意思(MRs),用于维基Data KG的组合。我们的评价使用BLEURT和人文评价度,显示10发音调后,Athena-Jur-Jur-体育和视频游戏域域的性能显著提高一致性和语系一致性。 在Athena-GPT-Neal-Neo中,通过直译的直译的直译率率率和直译为12GMLA。