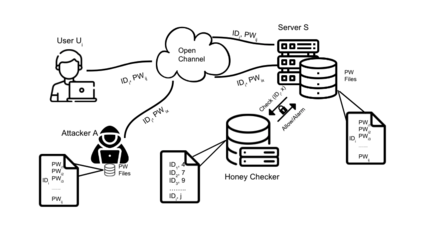
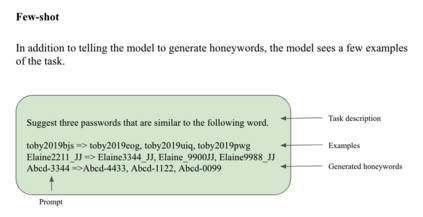
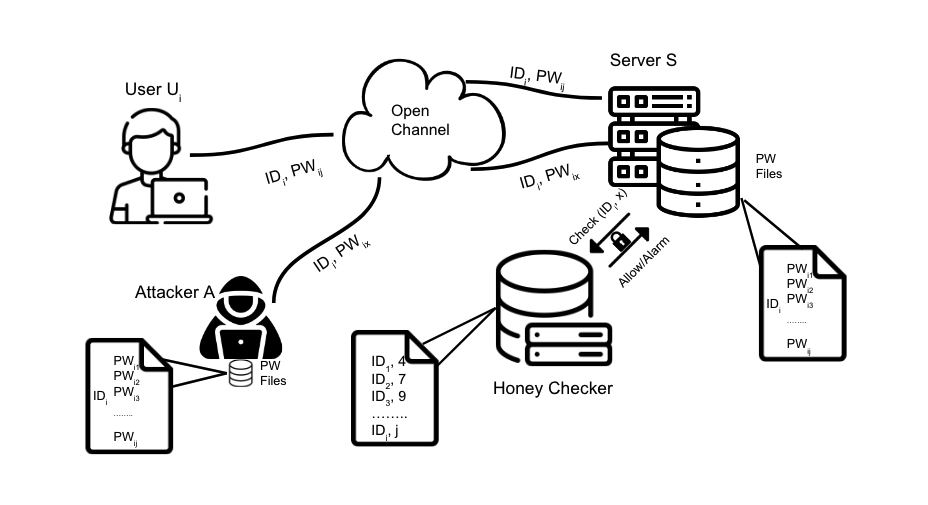
Honeywords are fictitious passwords inserted into databases in order to identify password breaches. The major difficulty is how to produce honeywords that are difficult to distinguish from real passwords. Although the generation of honeywords has been widely investigated in the past, the majority of existing research assumes attackers have no knowledge of the users. These honeyword generating techniques (HGTs) may utterly fail if attackers exploit users' personally identifiable information (PII) and the real passwords include users' PII. In this paper, we propose to build a more secure and trustworthy authentication system that employs off-the-shelf pre-trained language models which require no further training on real passwords to produce honeywords while retaining the PII of the associated real password, therefore significantly raising the bar for attackers. We conducted a pilot experiment in which individuals are asked to distinguish between authentic passwords and honeywords when the username is provided for GPT-3 and a tweaking technique. Results show that it is extremely difficult to distinguish the real passwords from the artifical ones for both techniques. We speculate that a larger sample size could reveal a significant difference between the two HGT techniques, favouring our proposed approach.
翻译:蜂鸣词是假口令,插入数据库以识别密码违规情况。主要困难在于如何制作难以与实际密码区分的蜂鸣词。虽然蜂鸣词的生成在过去曾受到广泛调查,但大多数现有研究都假定攻击者对用户不知情。如果攻击者利用用户个人可识别的信息(PII)和真正的密码(包括用户PII),这些蜂鸣词产生技术(HGTs)可能会完全失败。在本文中,我们提议建立一个更安全、更可靠的认证系统,使用现成的预先训练的语言模型,这些模型不需要在制作蜂鸣词方面接受进一步的实际密码培训,而同时保留相关实际密码的PII,从而大大提高攻击者的栏杆。我们进行了试点试验,在为GPT-3提供用户名时,请个人区分真实的密码和蜂鸣词。结果显示,很难区分这两种技术的真正密码与人工密码之间的差别。我们推测,更大的样本规模可能揭示两种HGTT技术之间的重大差异,有利于我们所提议的方法。