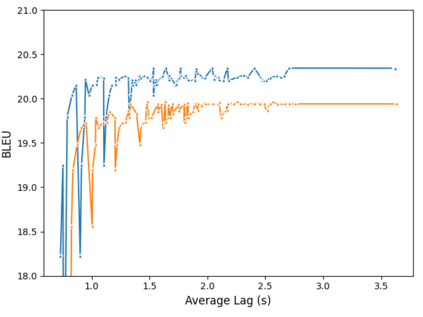
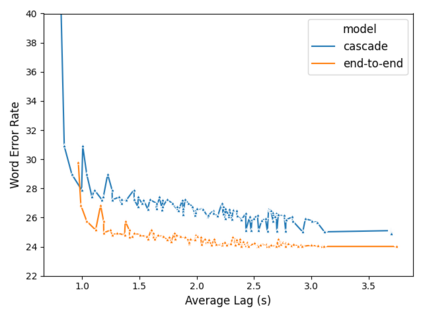
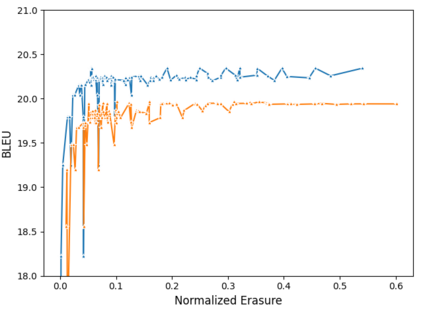
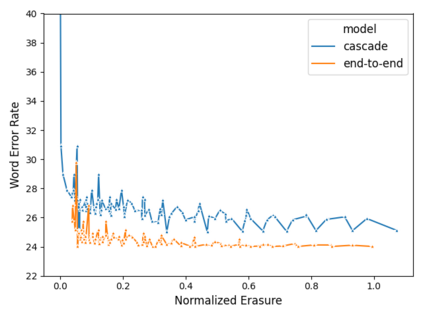
Using end-to-end models for speech translation (ST) has increasingly been the focus of the ST community. These models condense the previously cascaded systems by directly converting sound waves into translated text. However, cascaded models have the advantage of including automatic speech recognition output, useful for a variety of practical ST systems that often display transcripts to the user alongside the translations. To bridge this gap, recent work has shown initial progress into the feasibility for end-to-end models to produce both of these outputs. However, all previous work has only looked at this problem from the consecutive perspective, leaving uncertainty on whether these approaches are effective in the more challenging streaming setting. We develop an end-to-end streaming ST model based on a re-translation approach and compare against standard cascading approaches. We also introduce a novel inference method for the joint case, interleaving both transcript and translation in generation and removing the need to use separate decoders. Our evaluation across a range of metrics capturing accuracy, latency, and consistency shows that our end-to-end models are statistically similar to cascading models, while having half the number of parameters. We also find that both systems provide strong translation quality at low latency, keeping 99% of consecutive quality at a lag of just under a second.
翻译:使用端到端语言翻译模型(ST)日益成为ST社区的重点。这些模型通过直接将声波转换成翻译文本来压缩先前的级联系统。然而,级联模型的优点是,包括自动语音识别输出,这对各种实用的ST系统有用,这些系统经常在翻译的同时向用户显示记录誊本。为了缩小这一差距,最近的工作显示,在最终到端模型的可行性方面取得了初步进展,以产生这两种产出。然而,以往的所有工作都只是从连续的角度来看待这一问题,使这些方法在更具挑战性的流动设置中是否有效变得不确定。我们开发了一个端到端流模式,以再翻译方法为基础,并与标准级级联方法进行比较。我们还为联合案件引入了新的推论方法,将笔录和翻译在生成中互换,并消除了使用单独解码器的必要性。我们从一系列衡量准确性、耐久性和一致性的尺度上所作的评价表明,我们的端到端模型在统计上是否有效,在更具有挑战性的流式模型中,我们开发了一个端到端到端流模型,同时拥有了一半的精度,同时保持了99质量的一半。我们还发现两个系统在低质量下都提供。