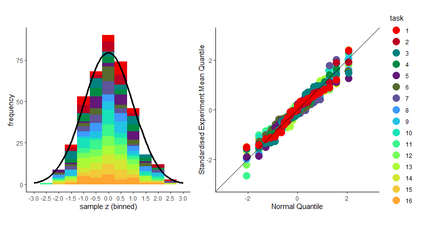
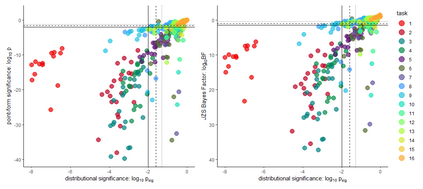
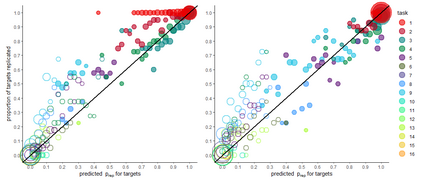
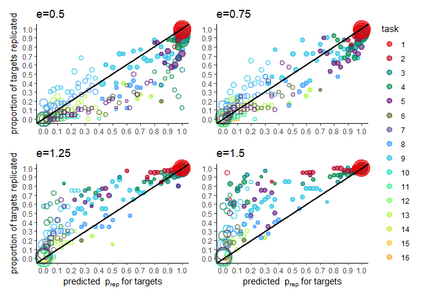
There is a well-known problem in Null Hypothesis Significance Testing: many statistically significant results fail to replicate in subsequent experiments. We show that this problem arises because standard `point-form null' significance tests consider only within-experiment but ignore between-experiment variation, and so systematically underestimate the degree of random variation in results. We give an extension to standard significance testing that addresses this problem by analysing both within- and between-experiment variation. This `distributional null' approach does not underestimate experimental variability and so is not overconfident in identifying significance; because this approach addresses between-experiment variation, it gives mathematically coherent estimates for the probability of replication of significant results. Using a large-scale replication dataset (the first `Many Labs' project), we show that many experimental results that appear statistically significant in standard tests are in fact consistent with random variation when both within- and between-experiment variation are taken into account in this approach. Further, grouping experiments in this dataset into `predictor-target' pairs we show that the predicted replication probabilities for target experiments produced in this approach (given predictor experiment results and the sample sizes of the two experiments) are strongly correlated with observed replication rates. Distributional null hypothesis testing thus gives researchers a statistical tool for identifying statistically significant and reliably replicable results.
翻译:在Null Hypothes Simplesity Convention 测试中有一个众所周知的问题:许多具有统计意义的结果未能在随后的实验中复制。我们表明,之所以出现这一问题,是因为标准的“点形无效”测试只考虑实验内部的实验,而忽略了实验之间的差异,因此系统地低估了结果随机变化的程度。我们扩大了标准意义测试的范围,通过分析实验内部和试验之间的差异来解决这个问题。这种“分配无效”方法不会低估实验的变异性,因此在确定重要性时不会过于自信;由于这种方法处理实验变异之间的问题,它为重大结果的复制概率提供了数学上一致的估计。我们利用大规模复制数据集(第一个“特征实验室”项目),我们表明,在标准测试中看起来具有重要统计意义的许多实验结果事实上与随机变异性相一致,因为在这一方法中考虑到内部和试验期间的变异性。此外,将这一数据集的实验归为“预测的复制性概率-目标”配对,我们显示,预测的可复制性概率和统计性实验的概率是这个观测到的统计实验的可靠模型。