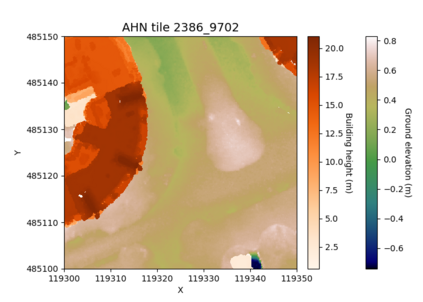
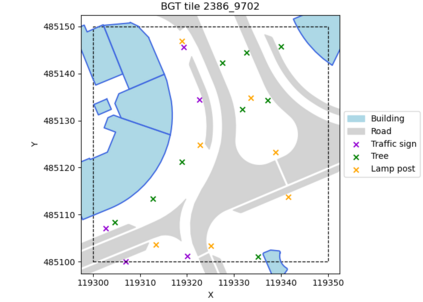
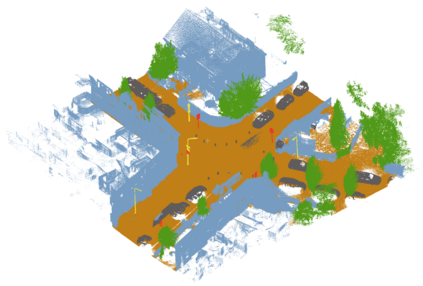
In this paper we describe an approach to semi-automatically create a labelled dataset for semantic segmentation of urban street-level point clouds. We use data fusion techniques using public data sources such as elevation data and large-scale topographical maps to automatically label parts of the point cloud, after which only limited human effort is needed to check the results and make amendments where needed. This drastically limits the time needed to create a labelled dataset that is extensive enough to train deep semantic segmentation models. We apply our method to point clouds of the Amsterdam region, and successfully train a RandLA-Net semantic segmentation model on the labelled dataset. These results demonstrate the potential of smart data fusion and semantic segmentation for the future of smart city planning and management.
翻译:在本文中,我们描述了一种半自动创建城市街道点云的语义分解标记数据集的方法。我们使用诸如海拔数据和大比例地形图等公共数据源的数据聚合技术,自动标出点云部分的标签,此后只需要有限的人力来检查结果并在必要时修改。这极大地限制了创建贴有标签的数据集所需的时间,该数据集足够广泛,足以培训深层次语义分解模型。我们运用了我们的方法来定位阿姆斯特丹地区的云,并成功地在标定数据集上培训了RandLA-Net语义分解模型。这些结果表明,智能数据混合和语义分解对于未来的智能城市规划和管理具有潜力。