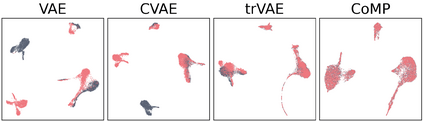
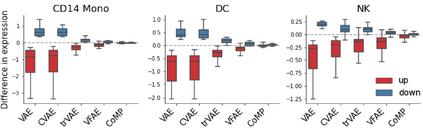
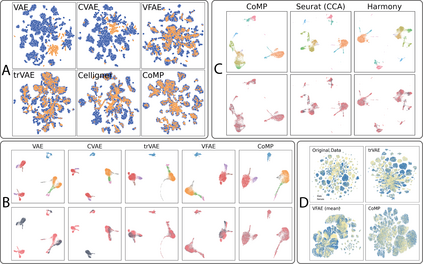
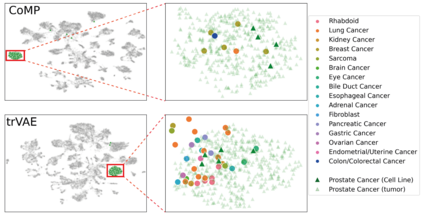
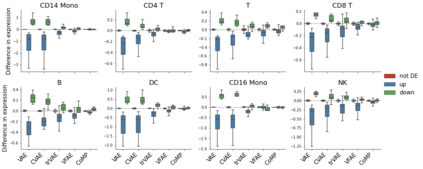
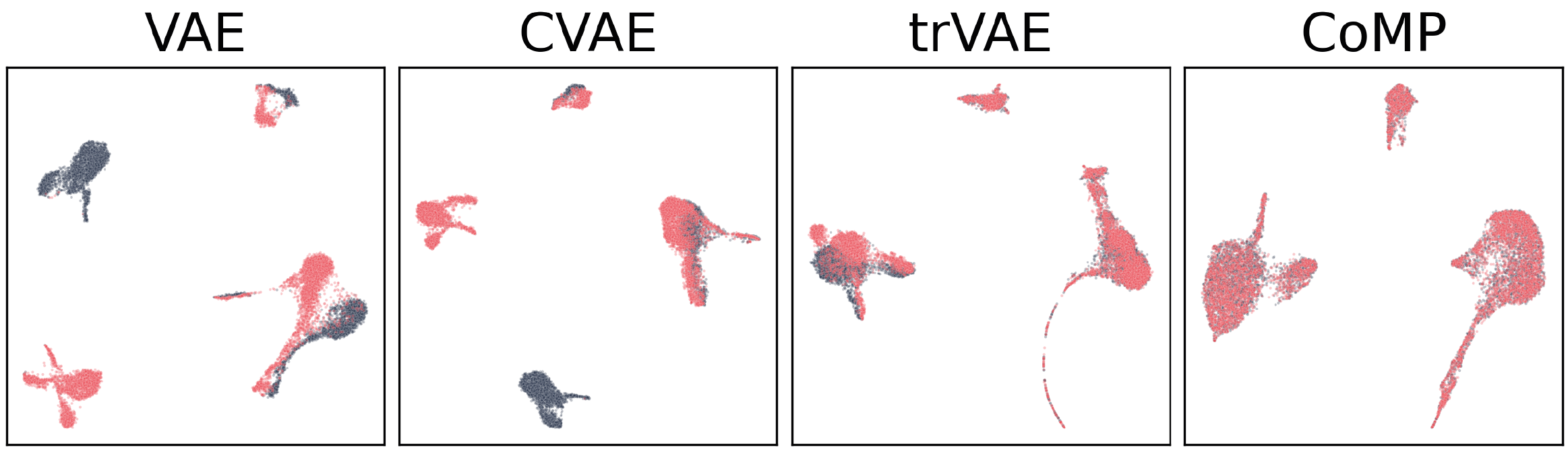
Learning meaningful representations of data that can address challenges such as batch effect correction and counterfactual inference is a central problem in many domains including computational biology. Adopting a Conditional VAE framework, we show that marginal independence between the representation and a condition variable plays a key role in both of these challenges. We propose the Contrastive Mixture of Posteriors (CoMP) method that uses a novel misalignment penalty defined in terms of mixtures of the variational posteriors to enforce this independence in latent space. We show that CoMP has attractive theoretical properties compared to previous approaches and we prove counterfactual identifiability of CoMP under additional assumptions. We demonstrate state of the art performance on a set of challenging tasks including aligning human tumour samples with cancer cell-lines, predicting transcriptome-level perturbation responses, and batch correction on single-cell RNA sequencing data. We also find parallels to fair representation learning and demonstrate that CoMP is competitive on a common task in the field.
翻译:学习有意义的数据表述方法,可以应对批量效果校正和反事实推断等挑战,这是包括计算生物学在内的许多领域的一个中心问题。采用条件性VAE框架,我们表明代表与条件变量之间的边际独立性在这两项挑战中都起着关键作用。我们提议了“ Posteres 相悖混合法(CoMP) ” (CoMP) 方法,该方法采用新颖的变异后遗物混合物定义的对称性惩罚,在潜在空间强制执行这一独立性。我们表明,与以往的做法相比,COMP 具有有吸引力的理论属性,而且我们证明,根据其他假设,COMP 具有相反的可识别性。我们展示了一套具有挑战性的任务的艺术性表现,包括将人类肿瘤样本与癌症细胞线相匹配、预测创记录层扰动反应和对单细胞RNA测序数据进行批次校正。我们还发现,与公平代表性学习相平行,并表明CMP在外地共同任务中具有竞争力。