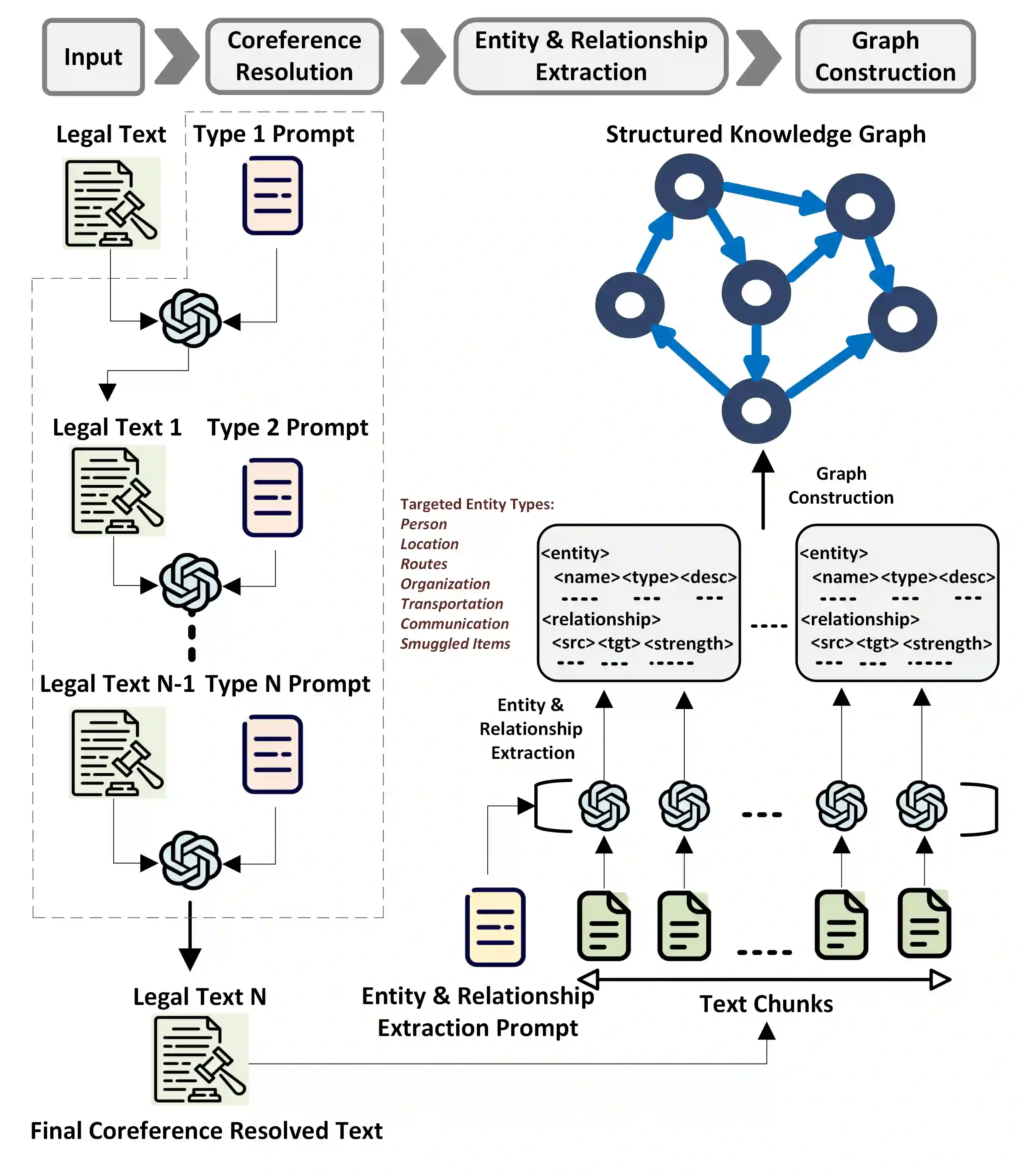
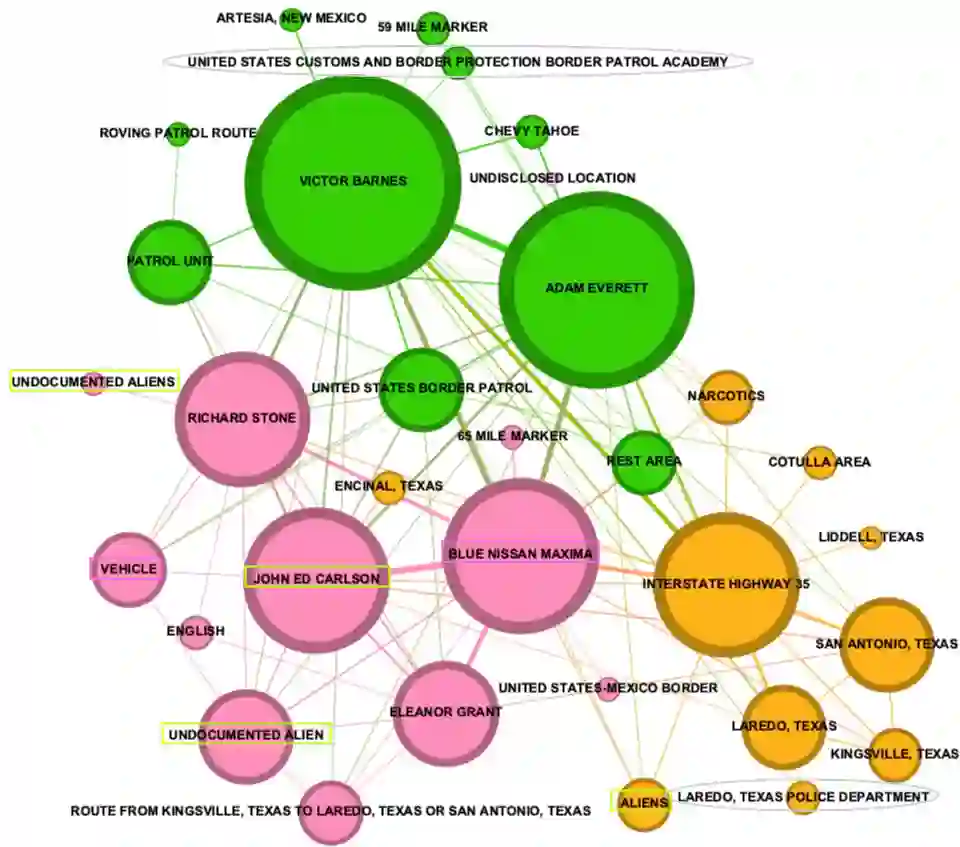
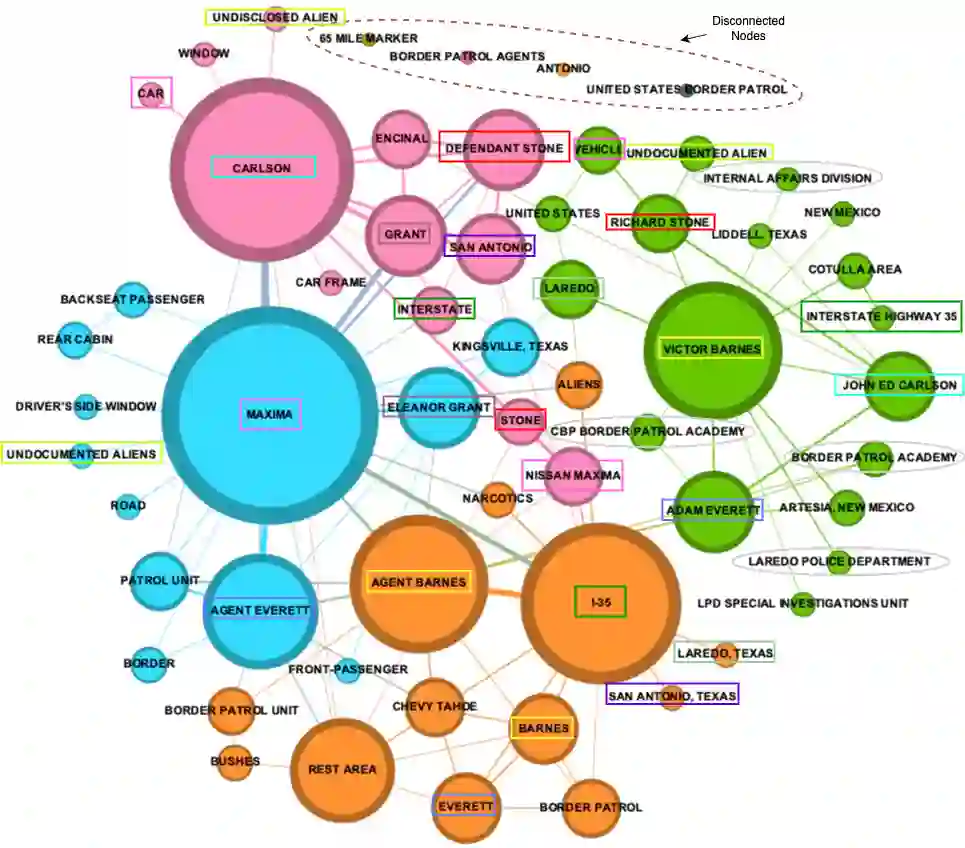
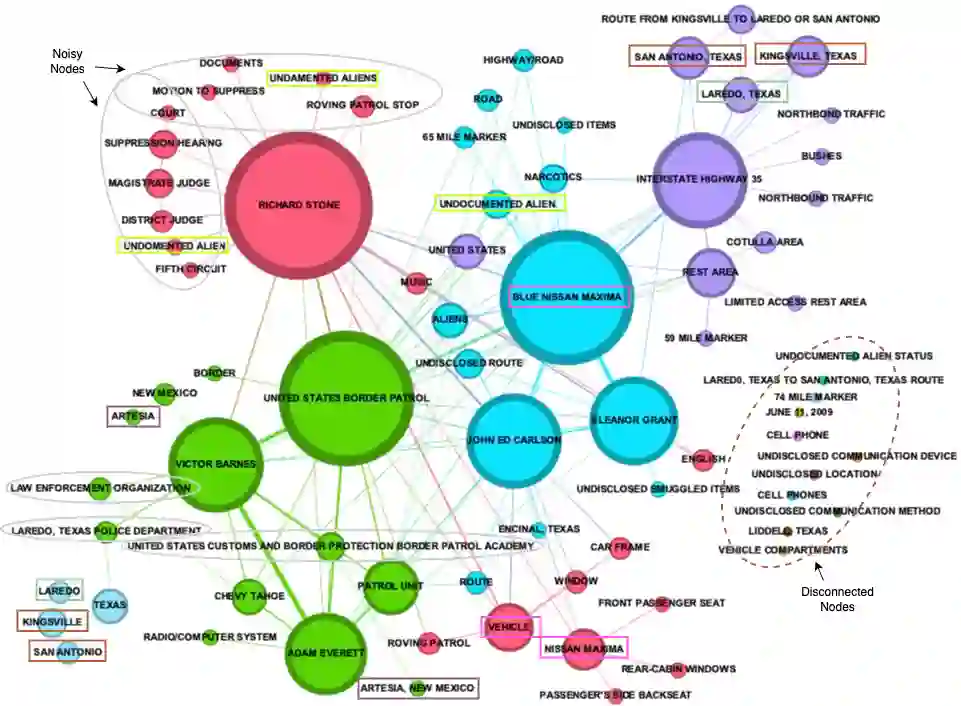
Human smuggling networks are increasingly adaptive and difficult to analyze. Legal case documents offer critical insights but are often unstructured, lexically dense, and filled with ambiguous or shifting references, which pose significant challenges for automated knowledge graph (KG) construction. While recent LLM-based approaches improve over static templates, they still generate noisy, fragmented graphs with duplicate nodes due to the absence of guided extraction and coreference resolution. The recently proposed CORE-KG framework addresses these limitations by integrating a type-aware coreference module and domain-guided structured prompts, significantly reducing node duplication and legal noise. In this work, we present a systematic ablation study of CORE-KG to quantify the individual contributions of its two key components. Our results show that removing coreference resolution results in a 28.32% increase in node duplication and a 4.32% increase in noisy nodes, while removing structured prompts leads to a 4.34% increase in node duplication and a 73.33% increase in noisy nodes. These findings offer empirical insights for designing robust LLM-based pipelines for extracting structured representations from complex legal texts.
翻译:人口走私网络日益具有适应性和分析难度。法律案例文档提供了关键洞察,但通常是非结构化、词汇密集且充满模糊或动态指代,这对自动化知识图谱(KG)构建构成了重大挑战。尽管最近基于大语言模型(LLM)的方法改进了静态模板,但由于缺乏引导式提取和指代消解,它们仍会生成带有重复节点的噪声和碎片化图谱。最近提出的CORE-KG框架通过整合类型感知的指代消解模块和领域引导的结构化提示,显著减少了节点重复和法律噪声。在本研究中,我们对CORE-KG进行了系统性的消融实验,以量化其两个关键组件的独立贡献。结果显示,移除指代消解会导致节点重复增加28.32%,噪声节点增加4.32%;而移除结构化提示则导致节点重复增加4.34%,噪声节点增加73.33%。这些发现为设计稳健的基于LLM的流程,以从复杂法律文本中提取结构化表示提供了实证依据。