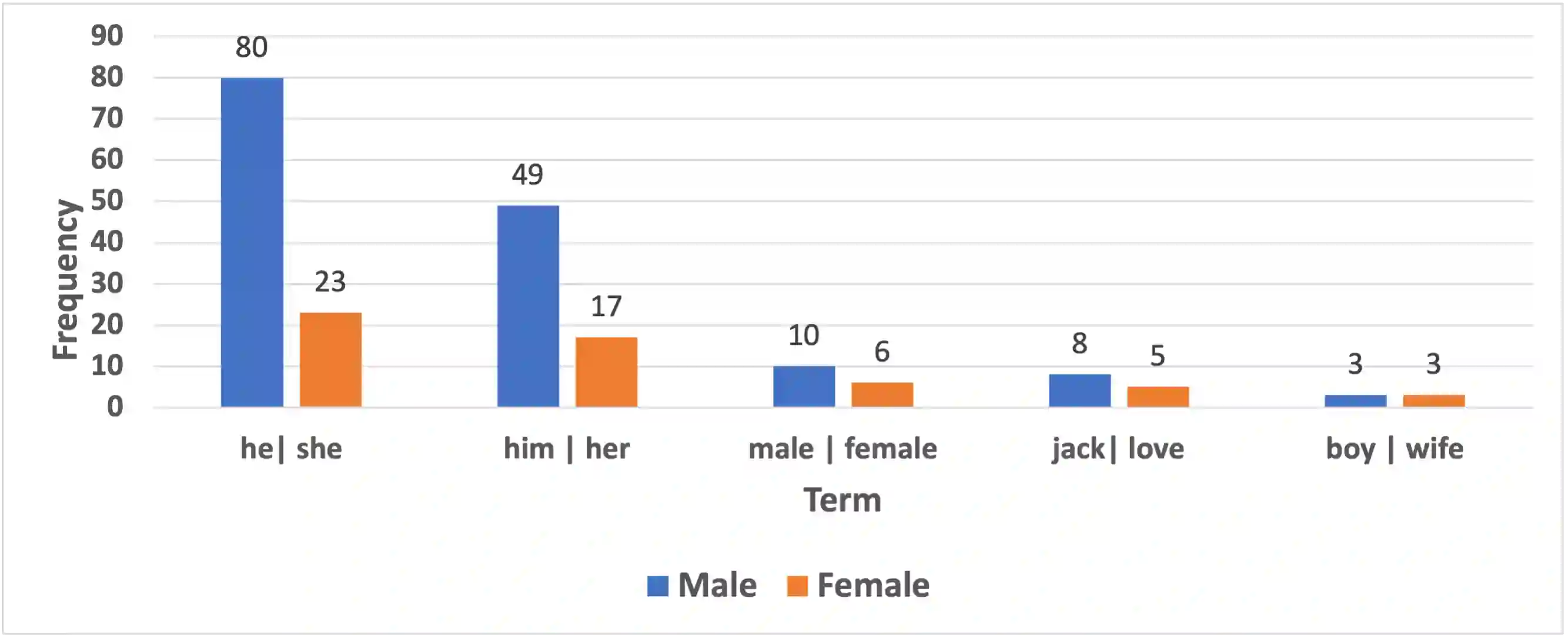
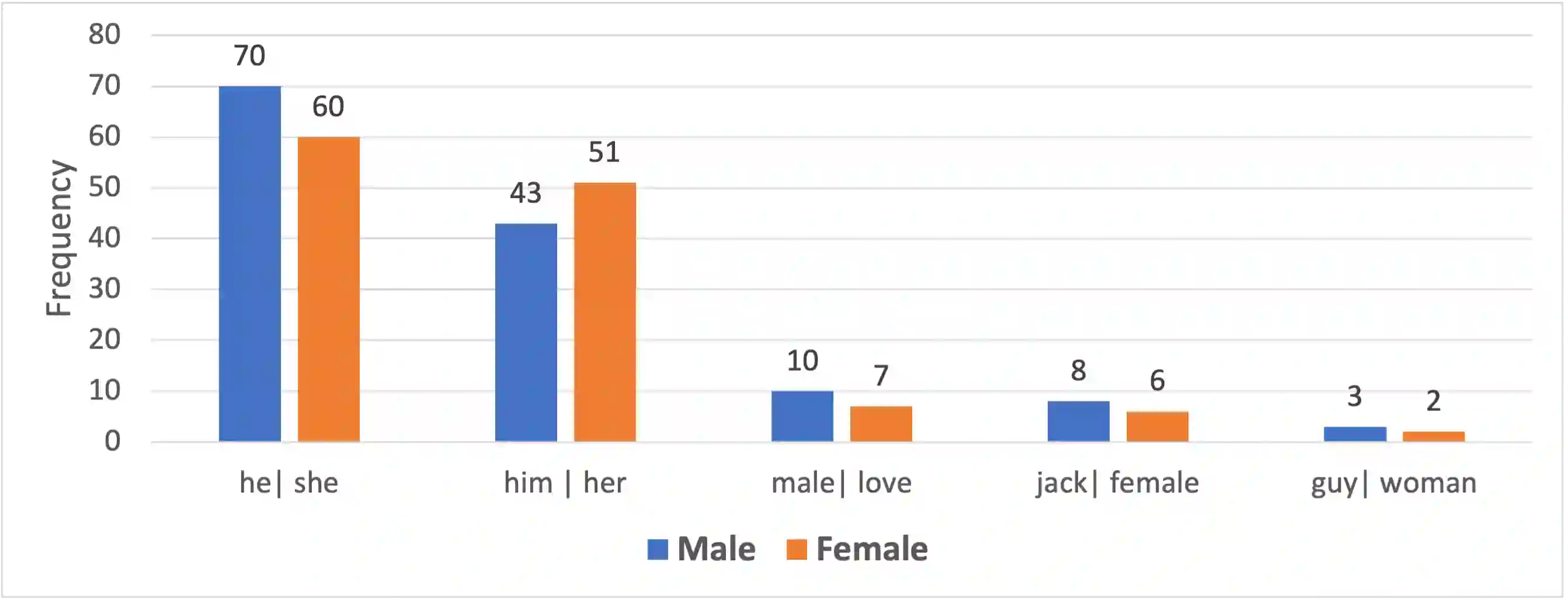
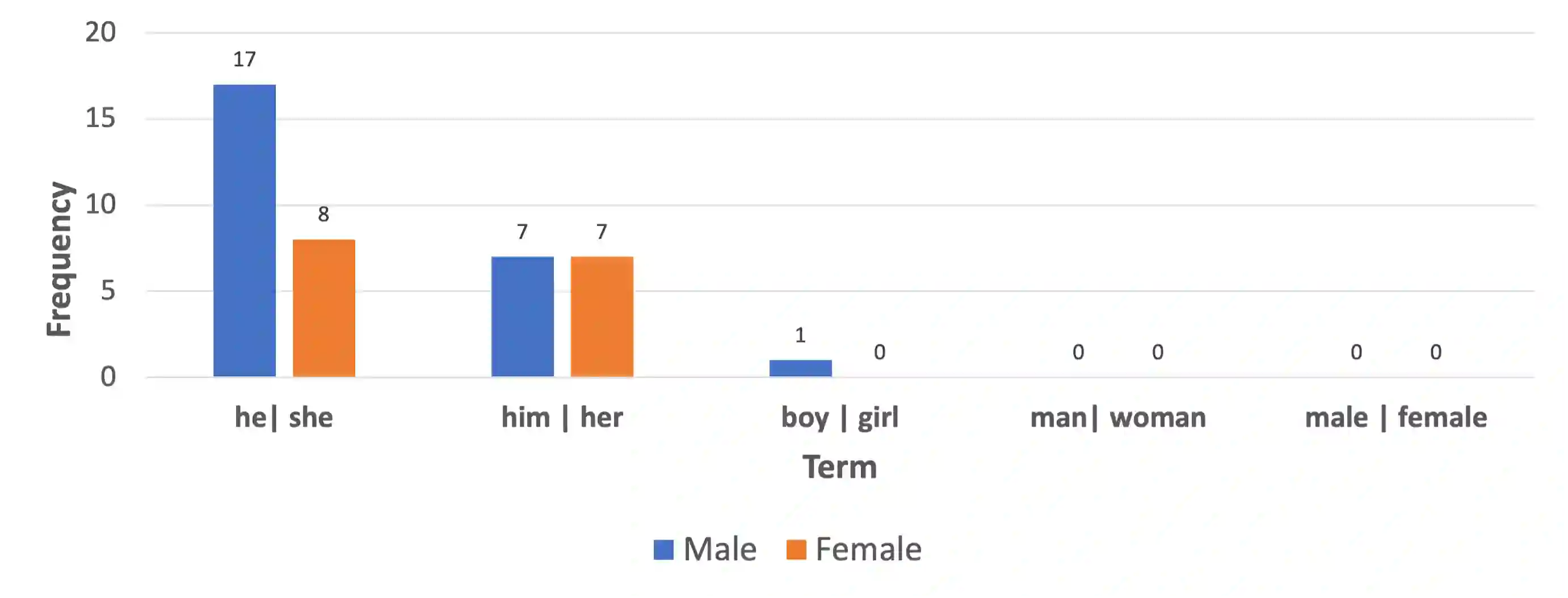
We investigate five English NLP benchmark datasets (on the superGLUE leaderboard) and two Swedish datasets for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Wino-gender diagnostic (AXg), Recognising Textual Entailment (RTE), Swedish CB, and SWEDN. Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to estimate and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large Swedish bias-labelled dataset (of 2 million samples), translated from the English version and train the SotA mT5 model on it. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We make the codes, model, and new dataset publicly available.
翻译:暂无翻译