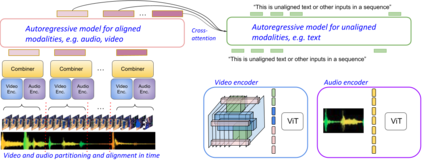
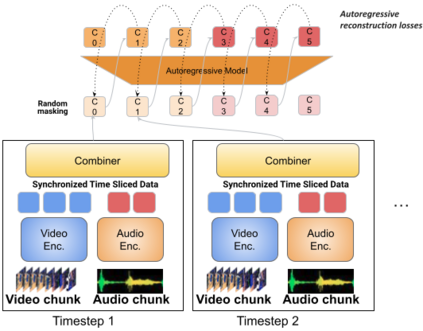
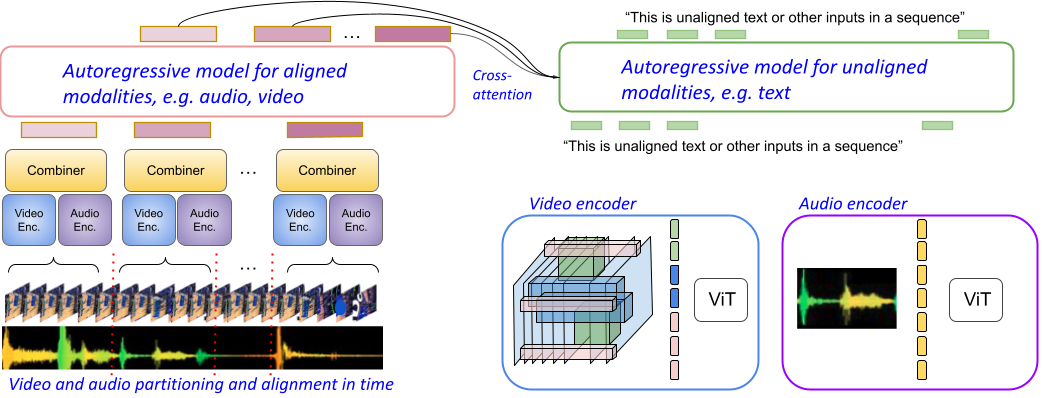
One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
翻译:暂无翻译