
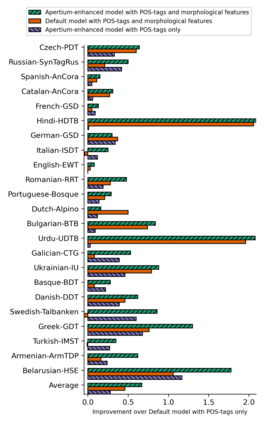
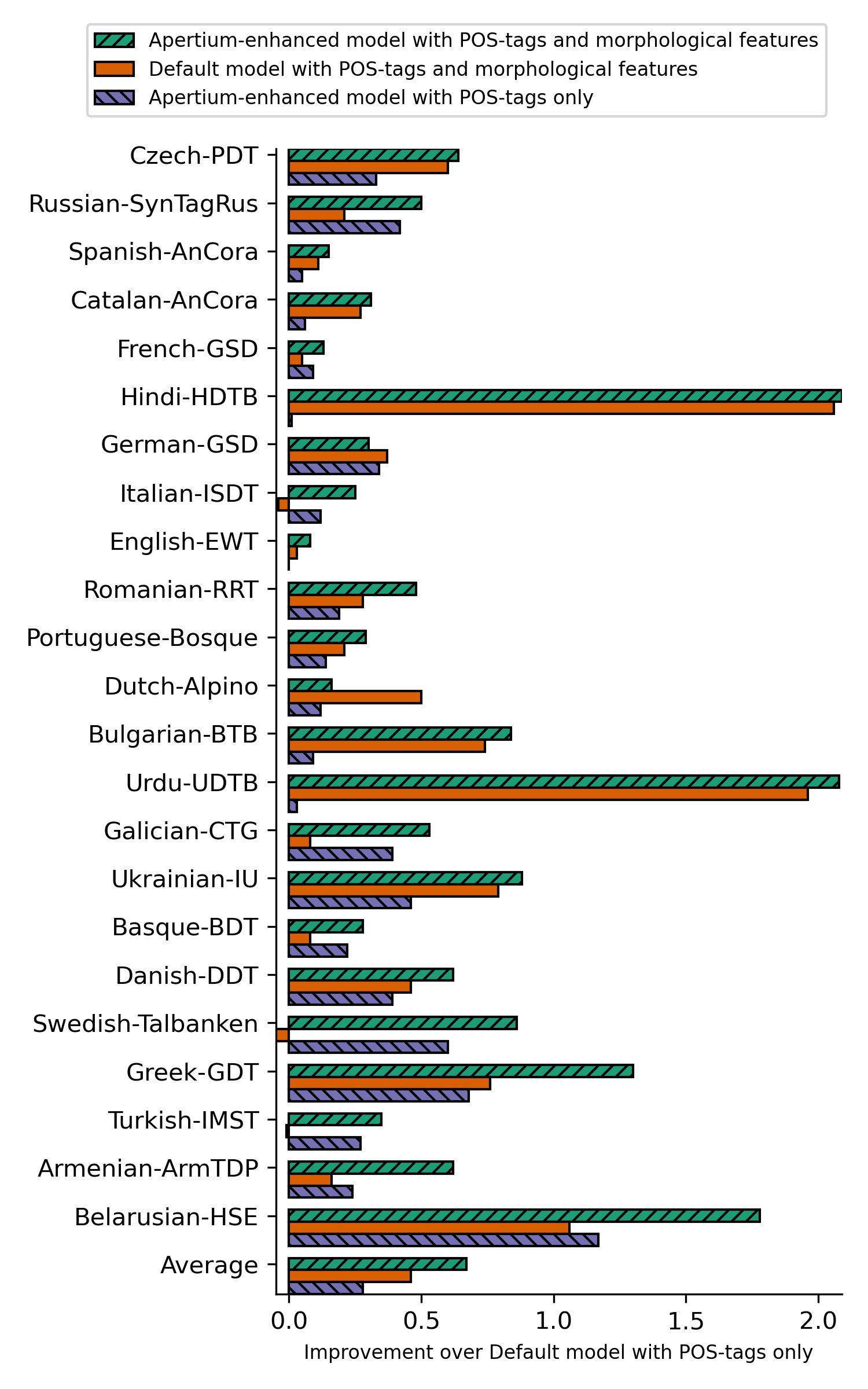
We propose a novel hybrid approach to lemmatization that enhances the seq2seq neural model with additional lemmas extracted from an external lexicon or a rule-based system. During training, the enhanced lemmatizer learns both to generate lemmas via a sequential decoder and copy the lemma characters from the external candidates supplied during run-time. Our lemmatizer enhanced with candidates extracted from the Apertium morphological analyzer achieves statistically significant improvements compared to baseline models not utilizing additional lemma information, achieves an average accuracy of 97.25% on a set of 23 UD languages, which is 0.55% higher than obtained with the Stanford Stanza model on the same set of languages. We also compare with other methods of integrating external data into lemmatization and show that our enhanced system performs considerably better than a simple lexicon extension method based on the Stanza system, and it achieves complementary improvements w.r.t. the data augmentation method.
翻译:我们建议一种新型的混合 Lemmatization 方法,通过从外部词汇或基于规则的系统中提取更多的 Lemmmas 来增强后继2seq神经模型。 在培训期间,强化的 emmatizer 学会通过连续解码器生成 Lemmas, 并复制运行期间外部候选人提供的 Lemma 字符 。 我们用从Apertium形态分析器中提取的候选人强化了 Lemma, 与基线模型相比,在统计上取得了显著的改进, 没有使用额外的 lemma 信息, 在一套23 UD 语言上实现了97.25%的平均精确度, 比斯坦福 Stanza 在同一套语言上的模型高出0.55 % 。 我们还比较了将外部数据纳入 Lemmatization 的其他方法, 并表明我们的强化系统比基于 Stanza 系统的简单词汇扩展方法要好得多, 并且实现了数据增强方法的补充性改进 w.r.t。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

