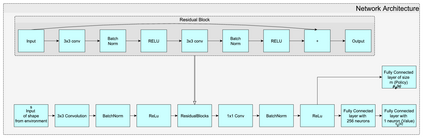
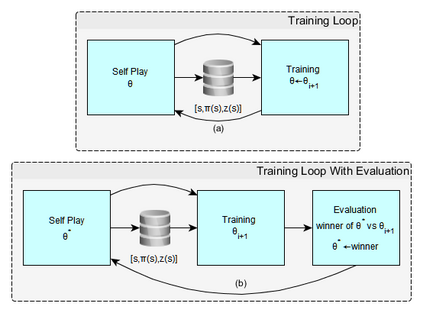
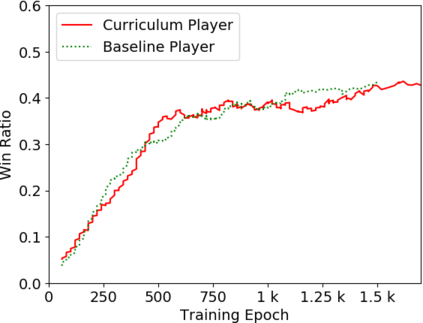
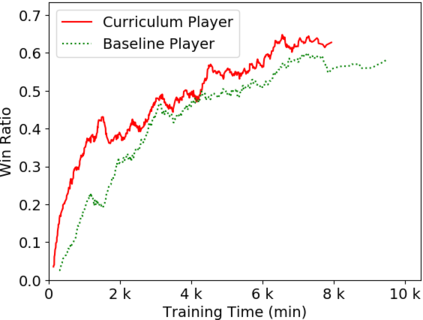
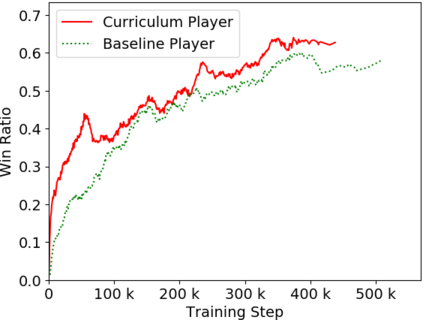
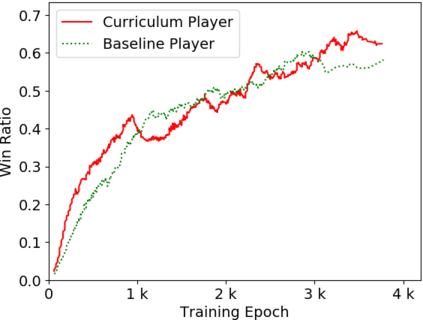
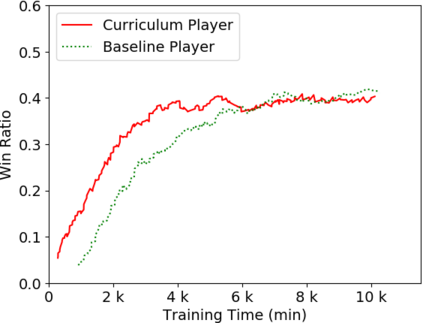
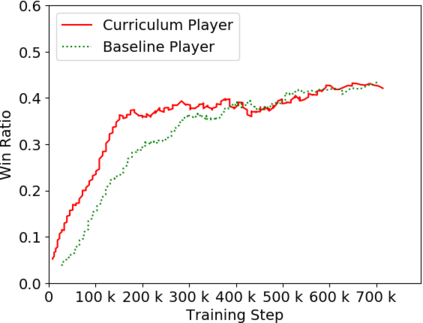
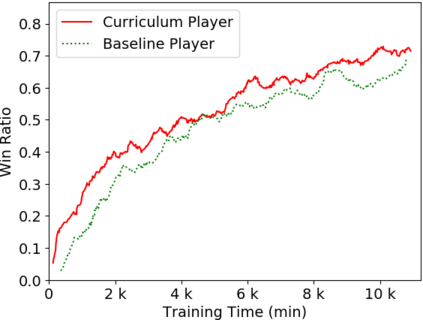
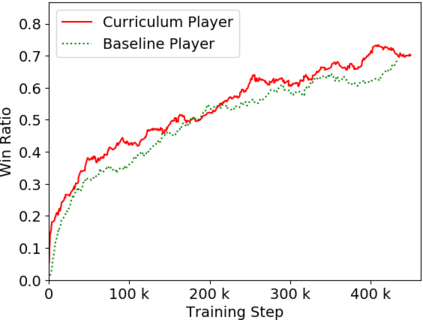
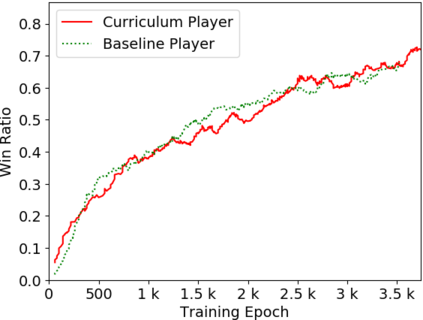
Humans tend to learn complex abstract concepts faster if examples are presented in a structured manner. For instance, when learning how to play a board game, usually one of the first concepts learned is how the game ends, i.e. the actions that lead to a terminal state (win, lose or draw). The advantage of learning end-games first is that once the actions which lead to a terminal state are understood, it becomes possible to incrementally learn the consequences of actions that are further away from a terminal state - we call this an end-game-first curriculum. Currently the state-of-the-art machine learning player for general board games, AlphaZero by Google DeepMind, does not employ a structured training curriculum; instead learning from the entire game at all times. By employing an end-game-first training curriculum to train an AlphaZero inspired player, we empirically show that the rate of learning of an artificial player can be improved during the early stages of training when compared to a player not using a training curriculum.
翻译:如果以有条不紊的方式展示实例,人类往往会更快地学习复杂的抽象概念。例如,当学习如何玩棋盘游戏时,通常最先学到的概念之一是游戏如何结束,即导致结束状态的行动(赢、输或抽 ) 。 学习最终游戏的优点是,一旦了解导致结束状态的行动,就有可能逐渐地了解远离终点状态的行动的后果——我们称之为“结束游戏第一”课程。目前,Google DeepMind的通用棋盘游戏最先进的机器学习玩家AlphaZero没有采用结构化的训练课程;而是从整个游戏中学习所有时间。我们通过使用结束游戏第一培训课程来培训阿尔法泽罗激发的玩家,我们从经验上表明,在培训的早期阶段,与不使用训练课程的玩家相比,人工玩家的学习率可以提高。