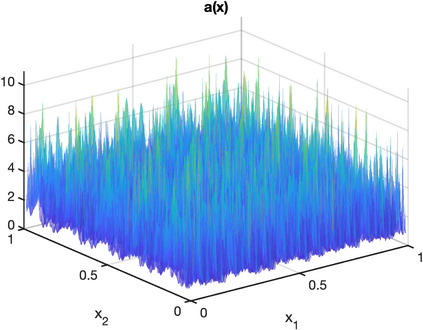
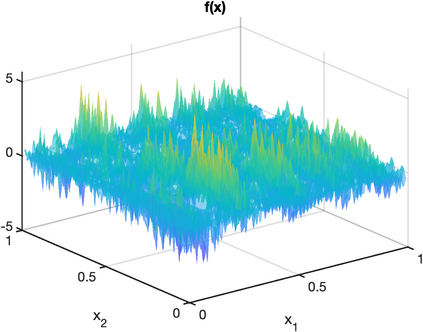
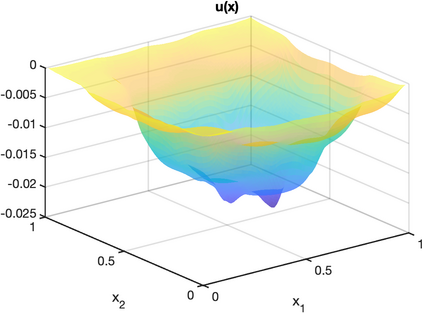
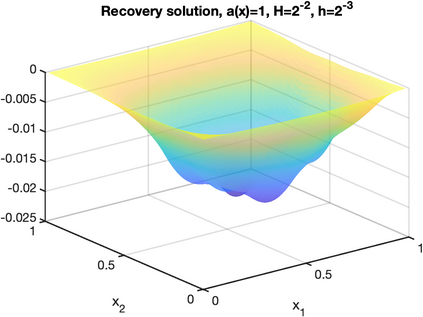
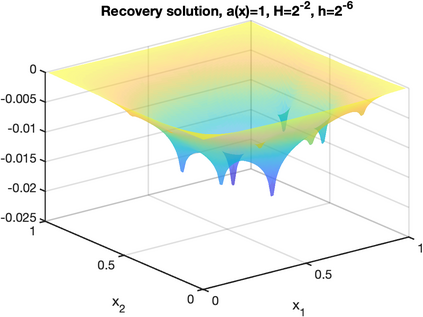
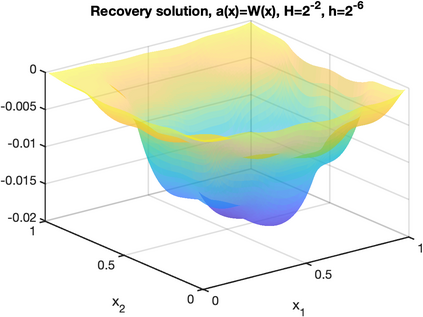
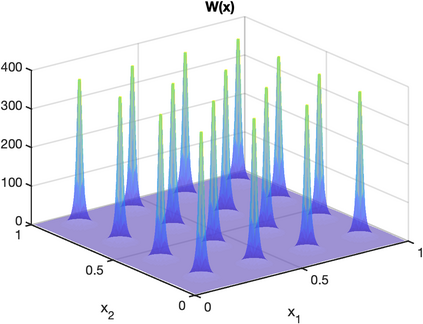
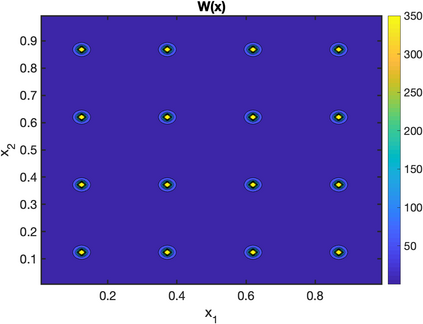
There is an intimate connection between numerical upscaling of multiscale PDEs and scattered data approximation of heterogeneous functions: the coarse variables selected for deriving an upscaled equation (in the former) correspond to the sampled information used for approximation (in the latter). As such, both problems can be thought of as recovering a target function based on some coarse data that are either artificially chosen by an upscaling algorithm, or determined by some physical measurement process. The purpose of this paper is then to study that, under such a setup and for a specific elliptic problem, how the lengthscale of the coarse data, which we refer to as the subsampled lengthscale, influences the accuracy of recovery, given limited computational budgets. Our analysis and experiments identify that, reducing the subsampling lengthscale may improve the accuracy, implying a guiding criterion for coarse-graining or data acquisition in this computationally constrained scenario, especially leading to direct insights for the implementation of the Gamblets method in the numerical homogenization literature. Moreover, reducing the lengthscale to zero may lead to a blow-up of approximation error if the target function does not have enough regularity, suggesting the need for a stronger prior assumption on the target function to be approximated. We introduce a singular weight function to deal with it, both theoretically and numerically. This work sheds light on the interplay of the lengthscale of coarse data, the computational costs, the regularity of the target function, and the accuracy of approximations and numerical simulations.
翻译:多尺度 PDE 的数值升降与各种函数的分散数据近似之间有着密切的联系: 用于计算升降方程式( 前者) 的粗粗变量( 前者) 与近似( 后者) 所使用的抽样信息相对。 因此, 两种问题都可以被认为是恢复基于某些粗粗数据的目标函数, 这些数据或者由升降算法人为地选择, 或者由某种物理测量程序人为地选择。 本文的目的是研究, 在这种设置之下, 对于具体的省略问题, 粗粗数据的长度尺度( 我们称之为小缩放方程式的长度)如何影响恢复的准确性, 而在有限的计算预算预算情况下, 我们的分析与实验发现, 降低亚粗度的长度可能会提高准确性, 意味着在这种计算上受限制的假设中, 特别是为了直接了解在数字同质化文献中采用 Gamblet 方法的情况。 此外, 将粗略数据的长度降为精确度( 我们称的缩略度) 的精确性( ), 如果目标值的精确性值的精确性函数并不经常地显示, 那么, 的精确的精确性计算值的精确性函数需要 。