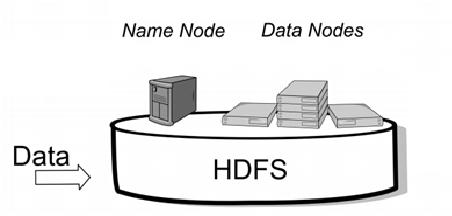
In this paper, a technology for massive data storage and computing named Hadoop is surveyed. Hadoop consists of heterogeneous computing devices like regular PCs abstracting away the details of parallel processing and developers can just concentrate on their computational problem. A Hadoop cluster is made of two parts: HDFs and Mapreduce. Hadoop cluster uses HDFS for data management. HDFS provides storage for input and output data in MapReduce jobs and is designed with abilities like high-fault tolerance, high-distribution capacity, and high throughput. It is also suitable for storing Terabyte data on clusters and it runs on flexible hardware like commodity devices.
翻译:本文调查了大规模数据存储和计算技术名称为Hadoop。 Hadoop由多种计算设备组成,如常规个人电脑,抽取平行处理的细节,开发者只能专注于计算问题。Hadoop集群由两部分组成:HDFs和Mapedexte。Hadoop集群将HDFS用于数据管理。HDFS提供在 MapRduce 工作中输入和输出数据的存储,其设计能力如高错容度、高分布能力和高吞吐量。它也适合存储Terabyte关于集群的数据,并使用商品装置等灵活硬件。