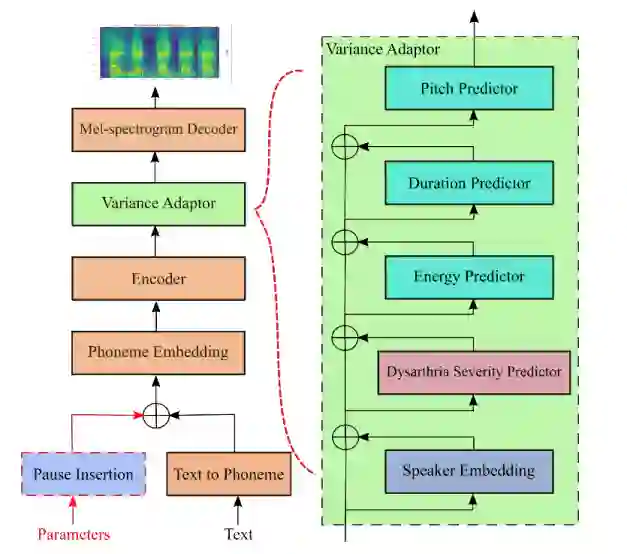
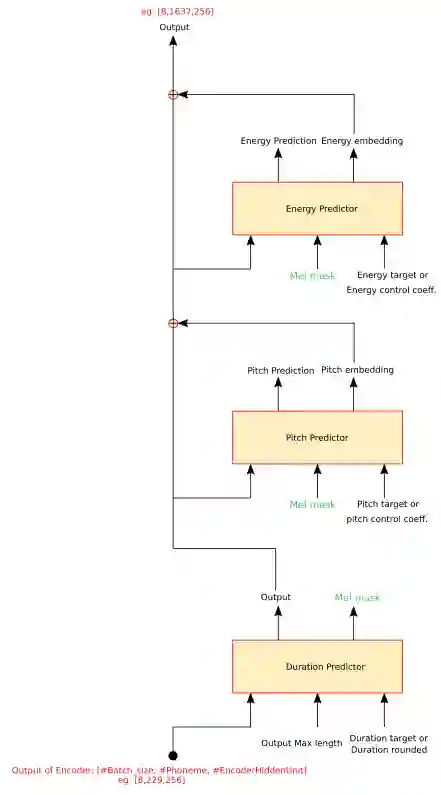
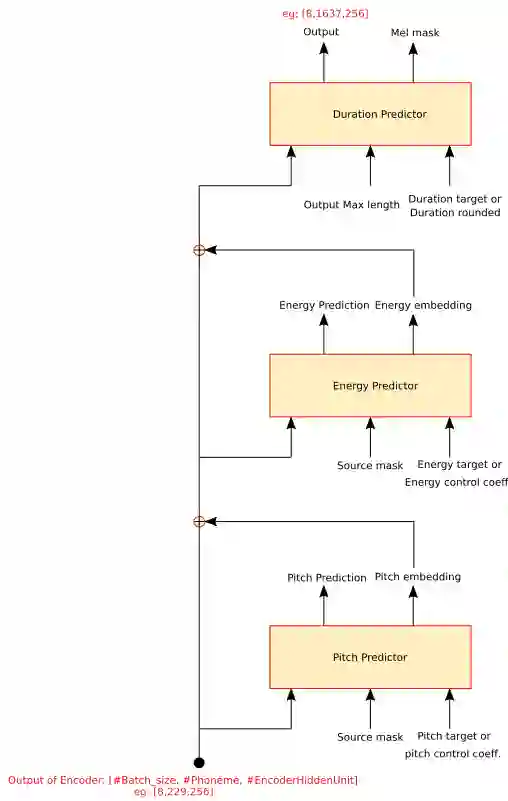
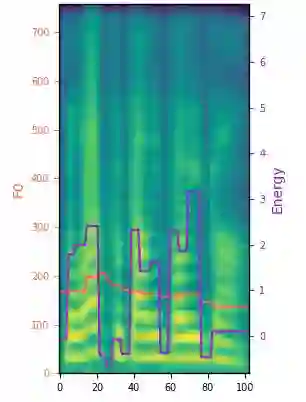
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems can help dysarthric talkers communicate more effectively. However, robust dysarthria-specific ASR requires a significant amount of training speech, which is not readily available for dysarthric talkers. This paper presents a new dysarthric speech synthesis method for the purpose of ASR training data augmentation. Differences in prosodic and acoustic characteristics of dysarthric spontaneous speech at varying severity levels are important components for dysarthric speech modeling, synthesis, and augmentation. For dysarthric speech synthesis, a modified neural multi-talker TTS is implemented by adding a dysarthria severity level coefficient and a pause insertion model to synthesize dysarthric speech for varying severity levels. To evaluate the effectiveness for synthesis of training data for ASR, dysarthria-specific speech recognition was used. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, and that the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Overall results on the TORGO database demonstrate that using dysarthric synthetic speech to increase the amount of dysarthric-patterned speech for training has significant impact on the dysarthric ASR systems. In addition, we have conducted a subjective evaluation to evaluate the dysarthric-ness and similarity of synthesized speech. Our subjective evaluation shows that the perceived dysartrhic-ness of synthesized speech is similar to that of true dysarthric speech, especially for higher levels of dysarthria
翻译:暂无翻译