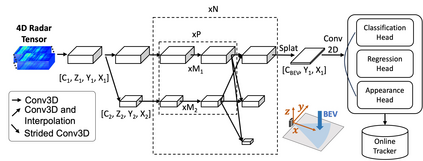
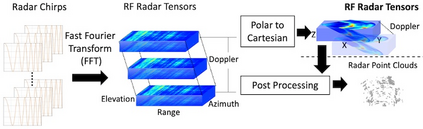
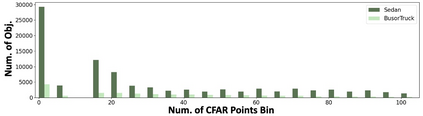
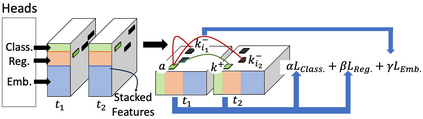
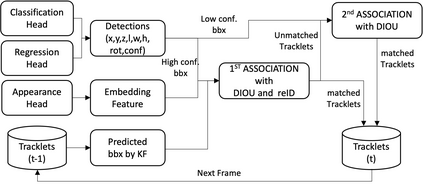
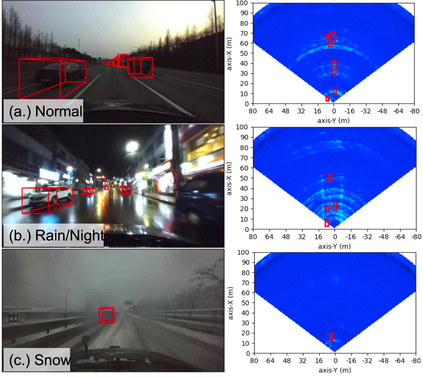
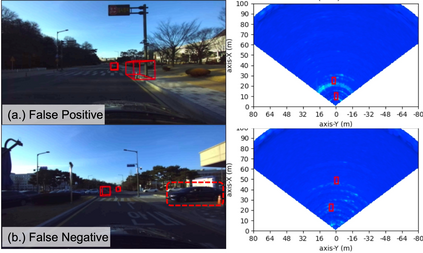
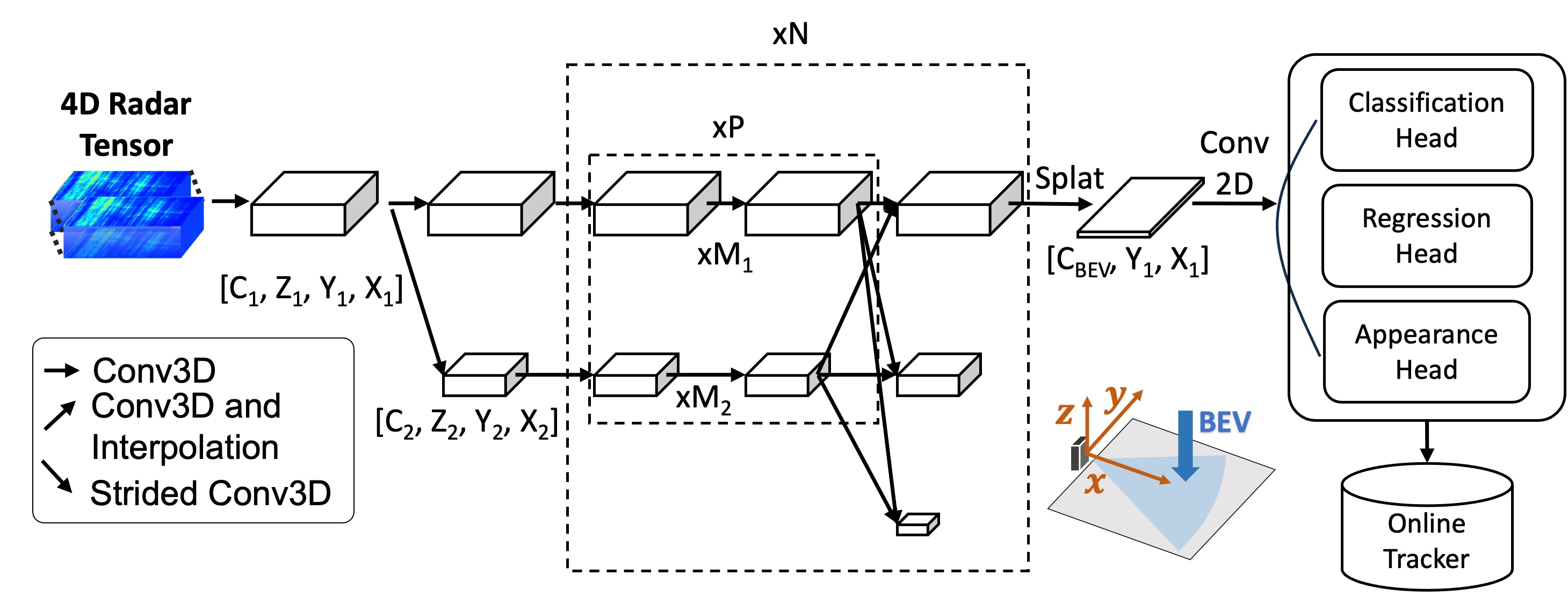
Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.
翻译:暂无翻译