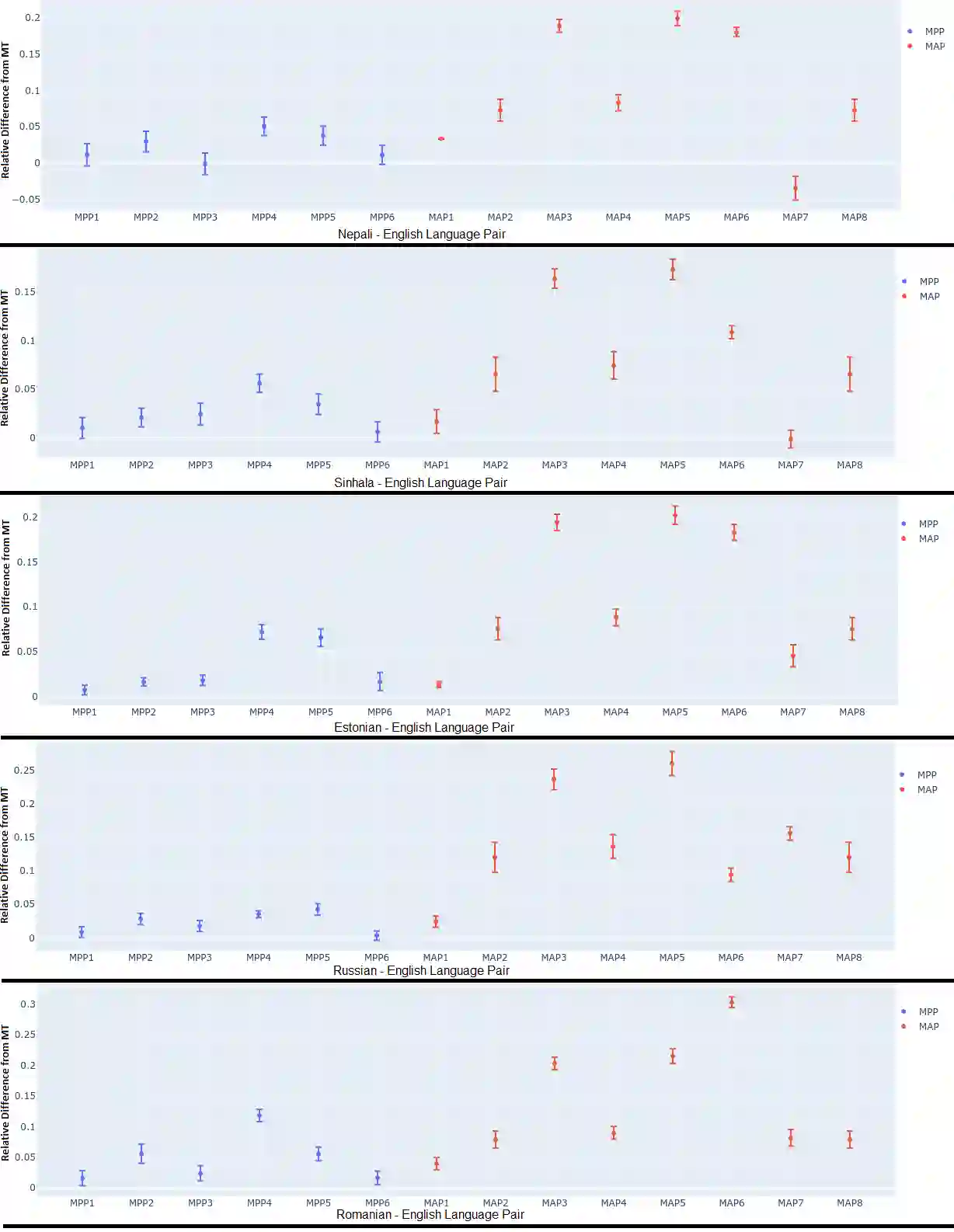
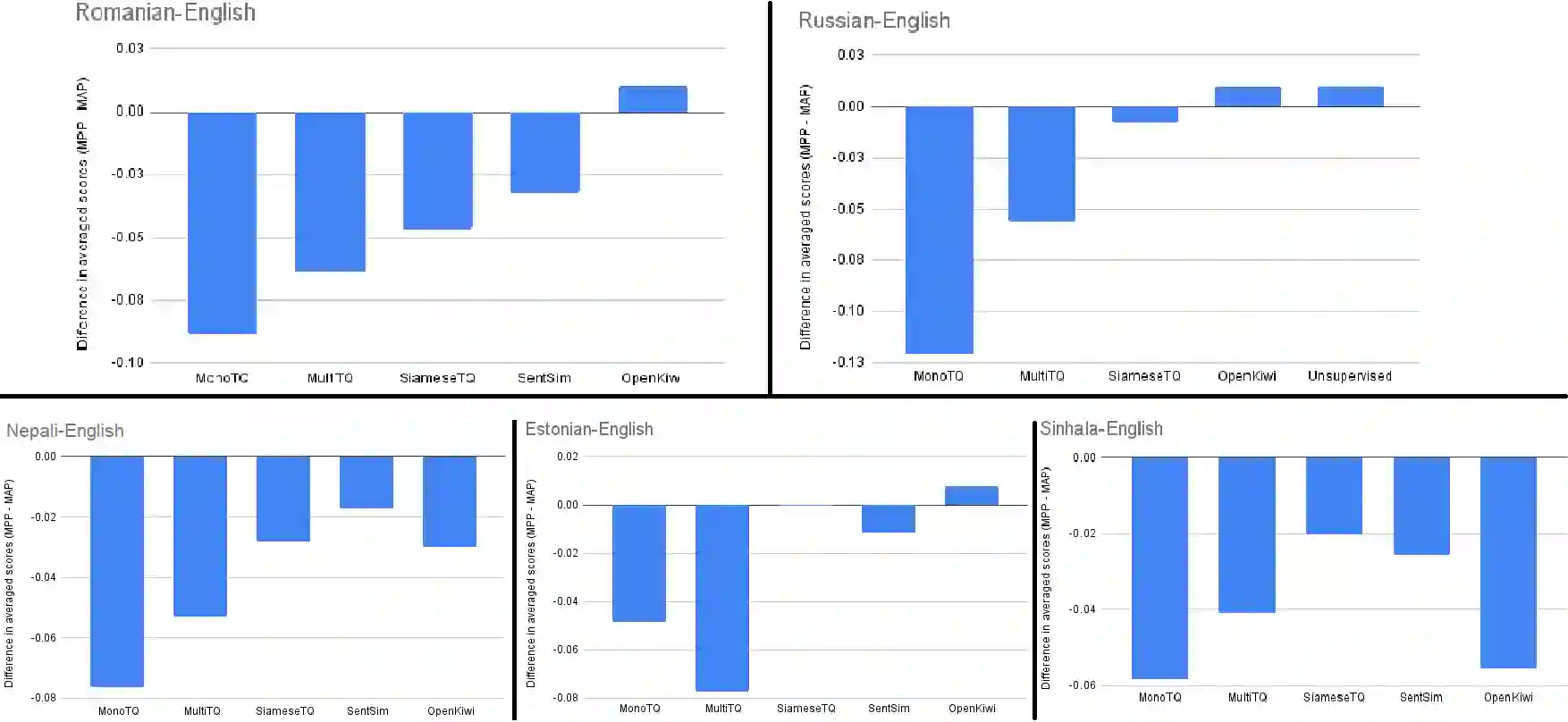
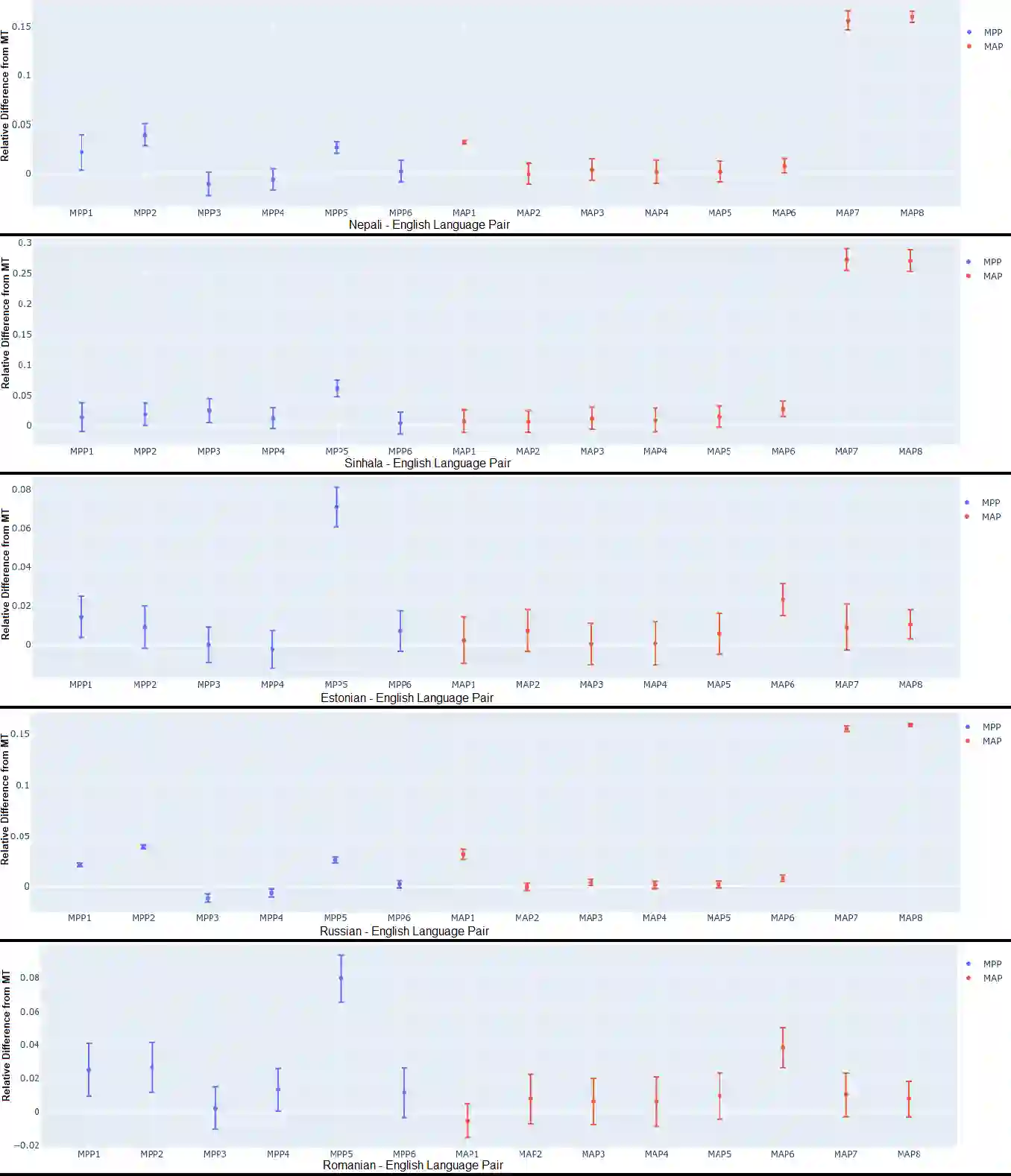
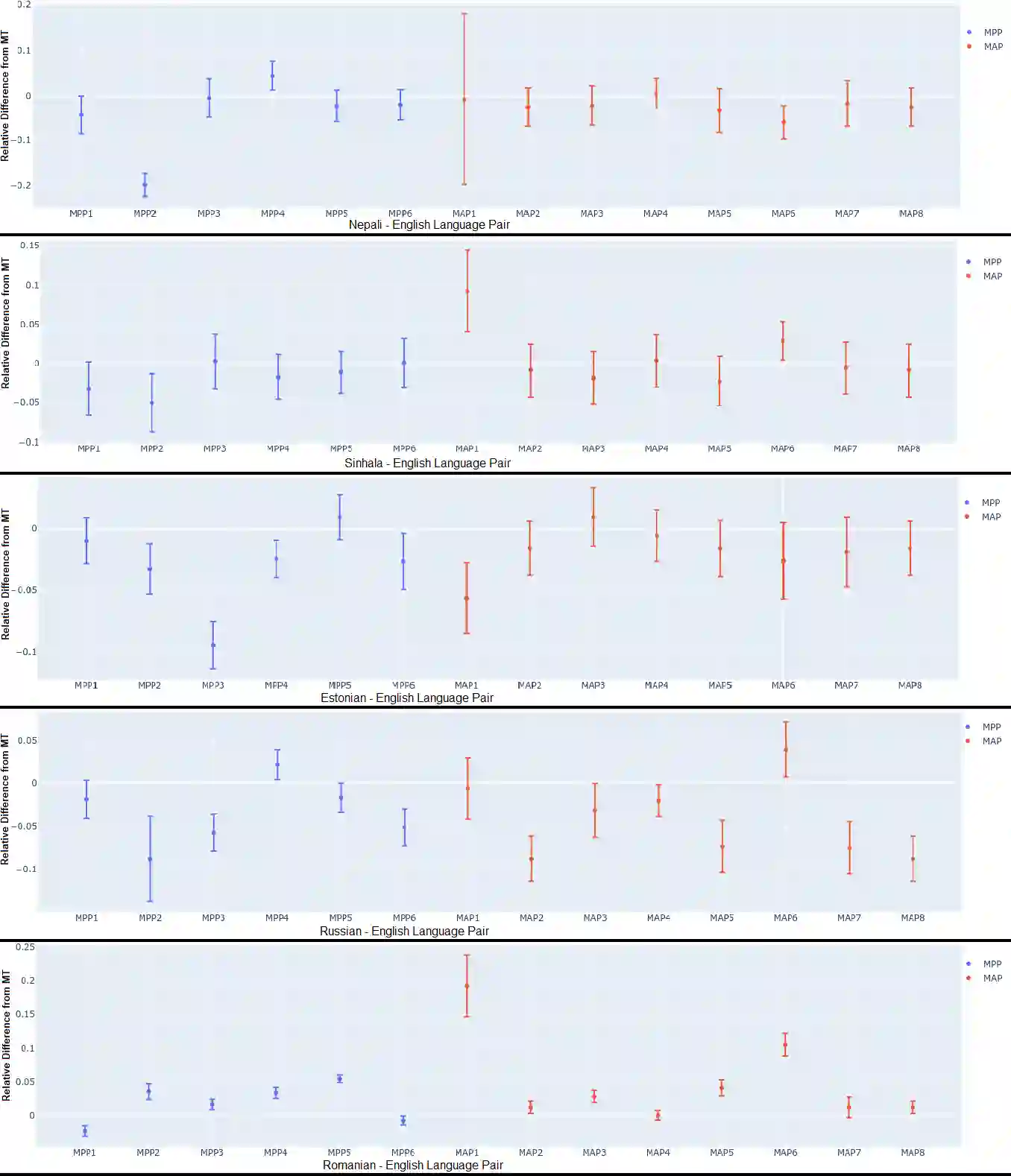
Current Machine Translation (MT) systems achieve very good results on a growing variety of language pairs and datasets. However, they are known to produce fluent translation outputs that can contain important meaning errors, thus undermining their reliability in practice. Quality Estimation (QE) is the task of automatically assessing the performance of MT systems at test time. Thus, in order to be useful, QE systems should be able to detect such errors. However, this ability is yet to be tested in the current evaluation practices, where QE systems are assessed only in terms of their correlation with human judgements. In this work, we bridge this gap by proposing a general methodology for adversarial testing of QE for MT. First, we show that despite a high correlation with human judgements achieved by the recent SOTA, certain types of meaning errors are still problematic for QE to detect. Second, we show that on average, the ability of a given model to discriminate between meaning-preserving and meaning-altering perturbations is predictive of its overall performance, thus potentially allowing for comparing QE systems without relying on manual quality annotation.
翻译:目前的机器翻译系统在越来越多的多种语文配对和数据集上取得了非常好的结果,然而,据知它们能够产生流畅的翻译产出,其中含有重要的含义错误,从而损害其在实践中的可靠性。质量估计(QE)是测试时自动评估MT系统性能的任务。因此,为了有用,QE系统应当能够发现这些错误。然而,在目前的评价做法中,这种能力尚有待测试,因为只有从与人类判断的相关性的角度来评估QE系统。在这项工作中,我们提出对质测试MTQE的一般方法来弥补这一差距。首先,我们表明,尽管与最近的SOTA的人类判断有高度的相关性,但某些类型的意义错误仍然对QE的检测有问题。第二,我们表明,平均而言,某一模式区分保留意义和改变意义之间的差别的能力是对其总体性能的预测,因此有可能允许在不依赖手动质量说明的情况下比较QE系统。