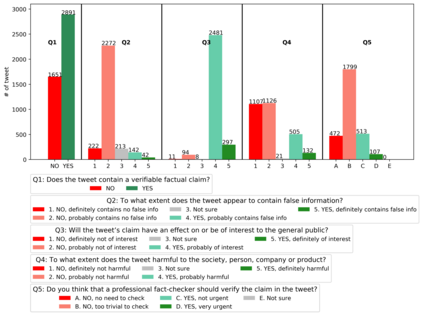
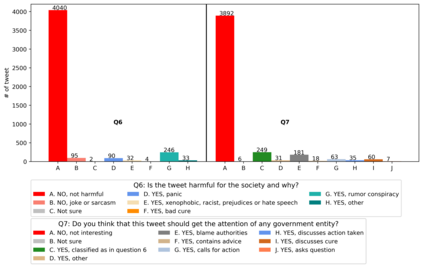
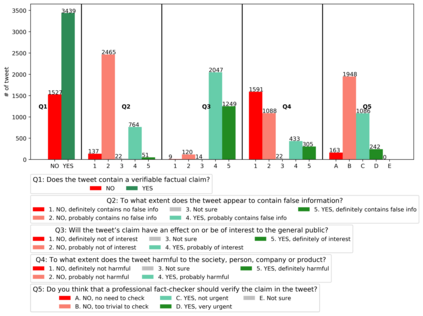
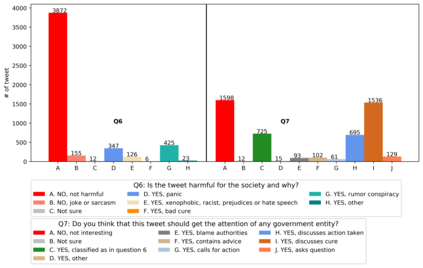
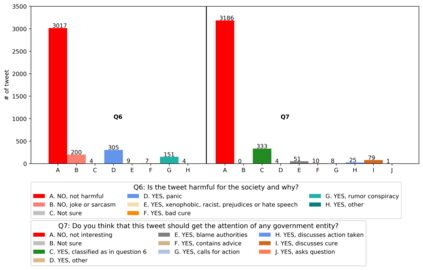
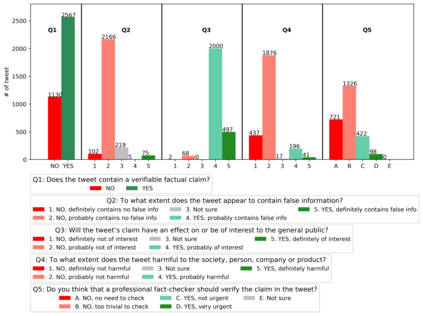
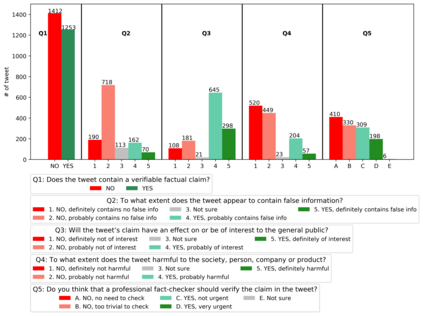
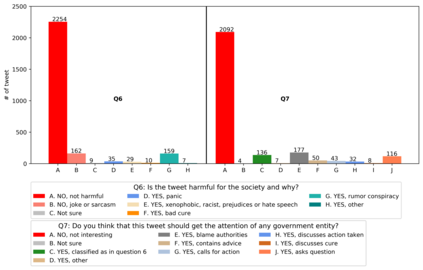
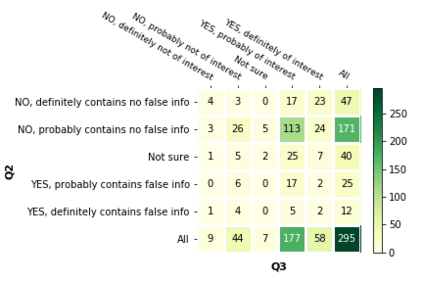
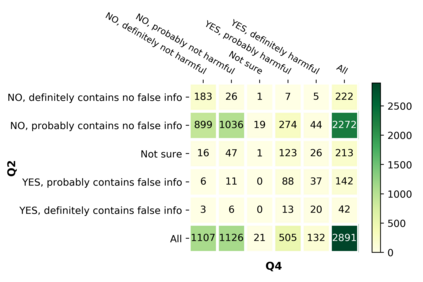
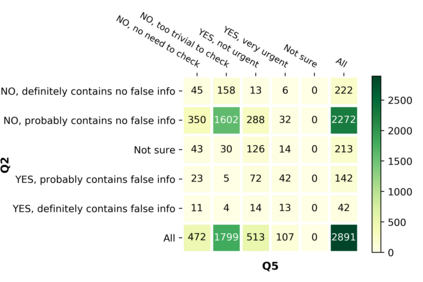
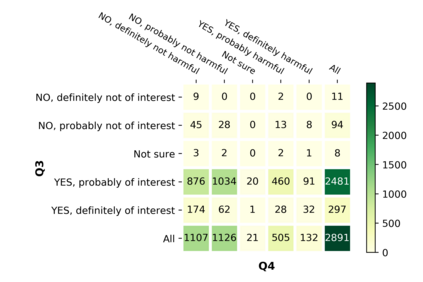
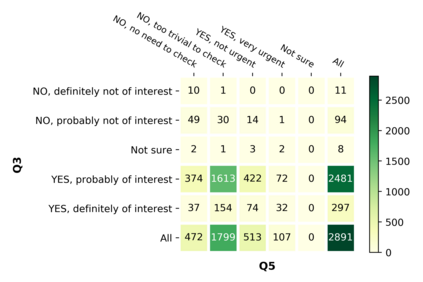
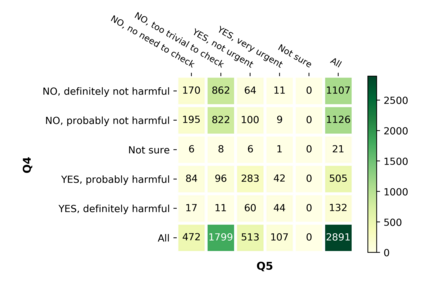
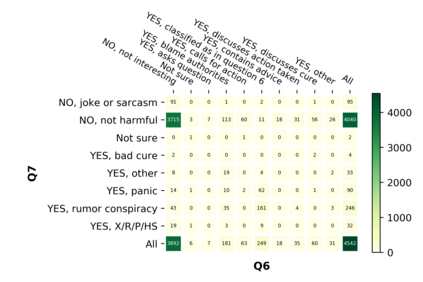
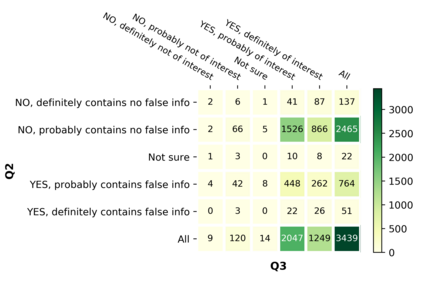
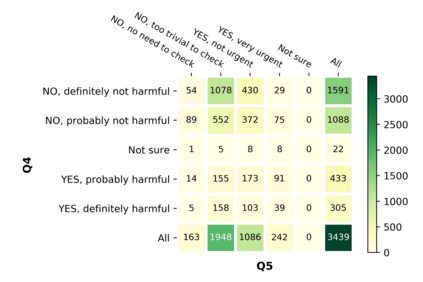
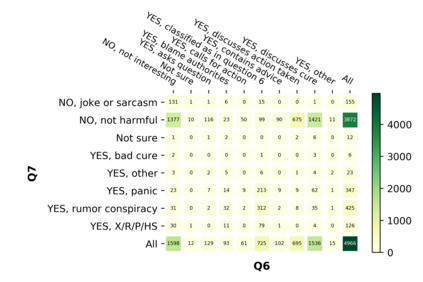
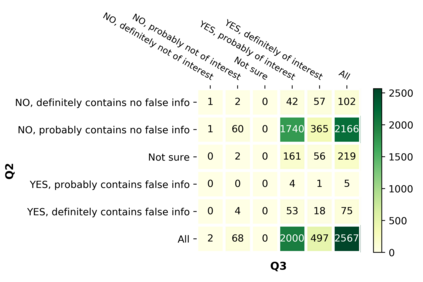
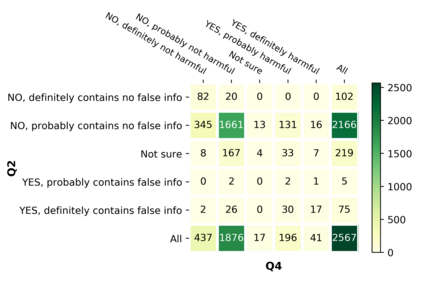
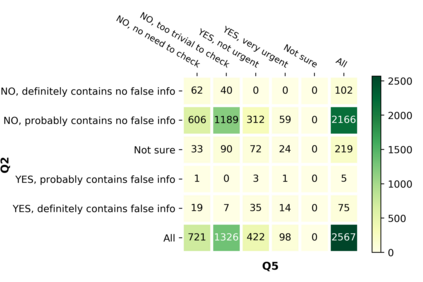
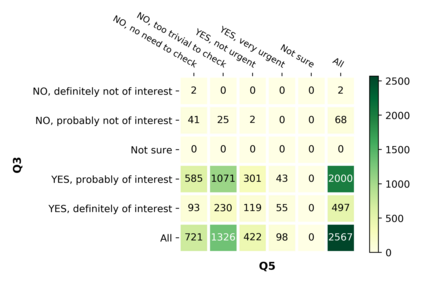
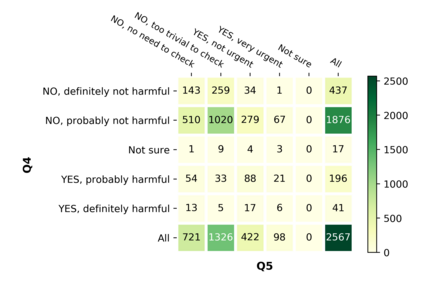
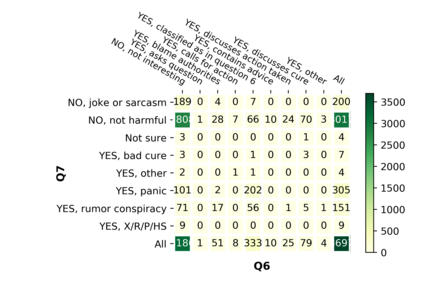
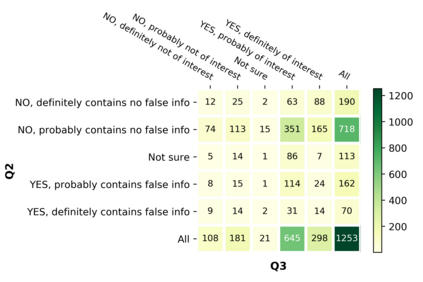
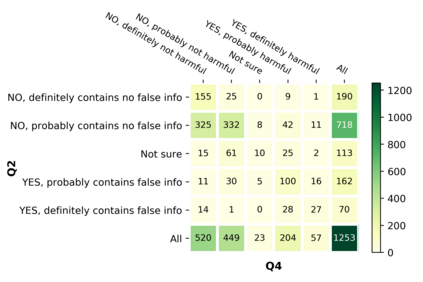
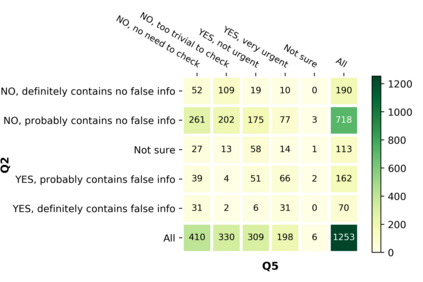
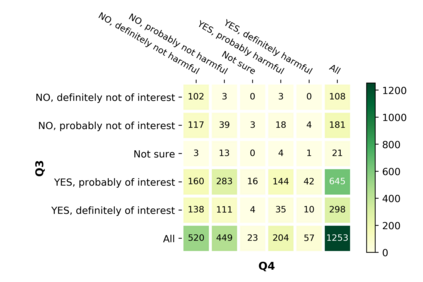
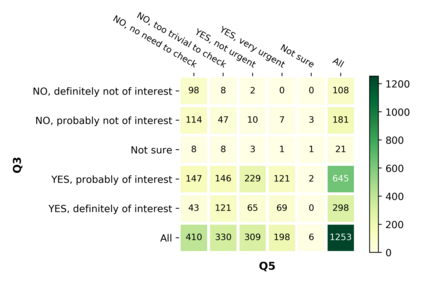
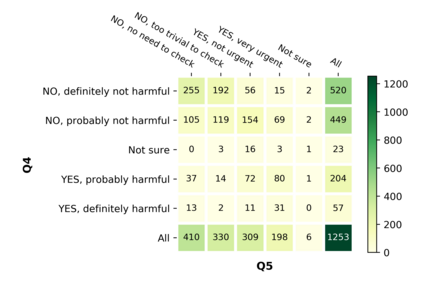
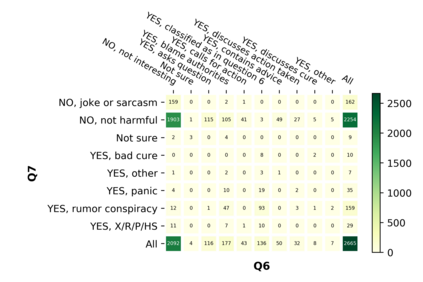
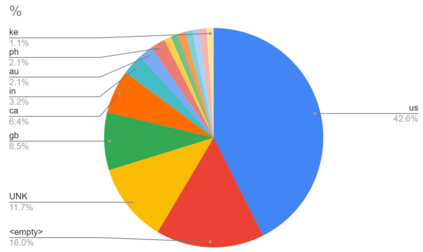
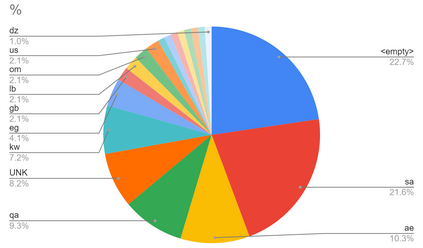
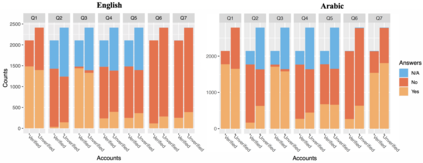
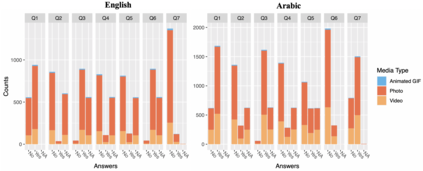
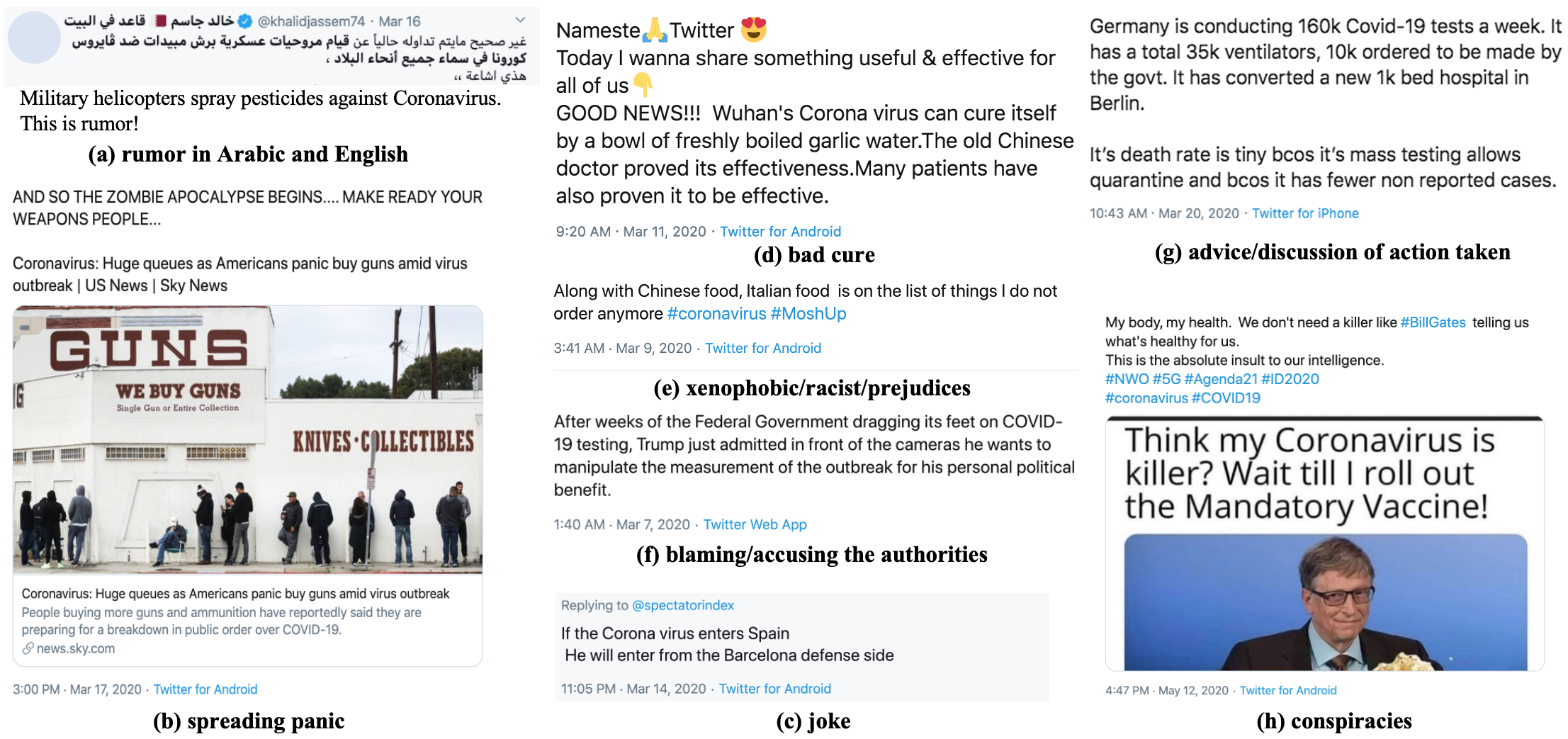
With the emergence of the COVID-19 pandemic, the political and the medical aspects of disinformation merged as the problem got elevated to a whole new level to become the first global infodemic. Fighting this infodemic has been declared one of the most important focus areas of the World Health Organization, with dangers ranging from promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic. Addressing the issue requires solving a number of challenging problems such as identifying messages containing claims, determining their check-worthiness and factuality, and their potential to do harm as well as the nature of that harm, to mention just a few. To address this gap, we release a large dataset of 16K manually annotated tweets for fine-grained disinformation analysis that (i) focuses on COVID-19, (ii) combines the perspectives and the interests of journalists, fact-checkers, social media platforms, policy makers, and society, and (iii) covers Arabic, Bulgarian, Dutch, and English. Finally, we show strong evaluation results using pretrained Transformers, thus confirming the practical utility of the dataset in monolingual vs. multilingual, and single task vs. multitask settings.
翻译:随着COVID-19大流行的出现,随着问题升级到一个全新的水平,假信息的政治和医学方面合在一起,成为第一个全球流行的焦点。对付这种假信息被宣布为世界卫生组织最重要的重点领域之一,其危险包括推广假疗法、谣言和阴谋理论,以传播仇外心理和恐慌。解决这个问题需要解决一些具有挑战性的问题,例如查明含有主张的信息,确定它们是否可靠和真实,它们有可能造成伤害,以及这种伤害的性质,仅举几个例子。为了弥补这一差距,我们发布了16K的大型数据集,我们用人工制作了16K的附加注释的推文,用于精细的虚假信息分析:(一) 侧重于COVID-19,(二) 将记者、事实检查者、社会媒体平台、决策者和社会的观点和利益结合起来,以及(三) 涵盖阿拉伯语、保加利亚语、荷兰语和英语。最后,我们用经过预先培训的变换者展示了强有力的评价结果,从而证实了单语对多语言、语言和单项任务设置的实用性。