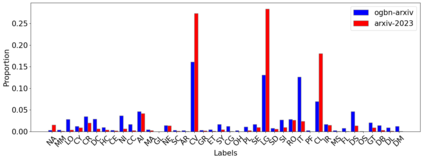
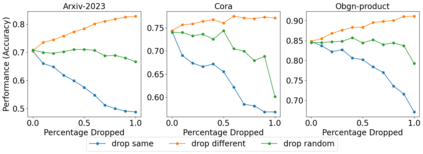
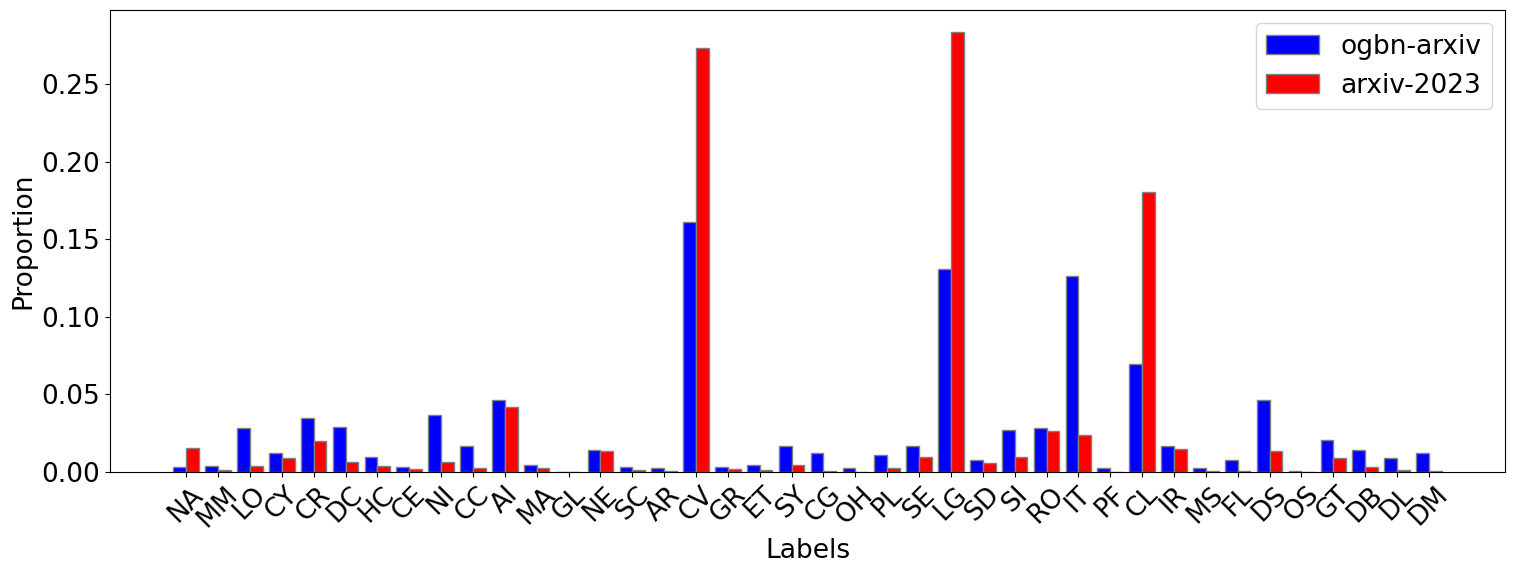
This paper studies Large Language Models (LLMs) for structured data--particularly graphs--a crucial data modality that remains underexplored in the LLM literature. We aim to understand when and why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs on node classification tasks. To address the ``when'' question, we examine a variety of prompting methods for encoding structural information, in settings where textual node features are either rich or scarce. For the ``why'' questions, we probe into two potential contributing factors to the LLM performance: data leakage and homophily. Our exploration of these questions reveals that (i) LLMs can benefit from structural information, especially when textual node features are scarce; (ii) there is no substantial evidence indicating that the performance of LLMs is significantly attributed to data leakage; and (iii) the performance of LLMs on a target node is strongly positively related to the local homophily ratio of the node.
翻译:暂无翻译