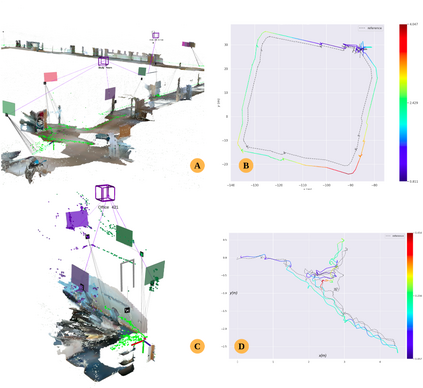
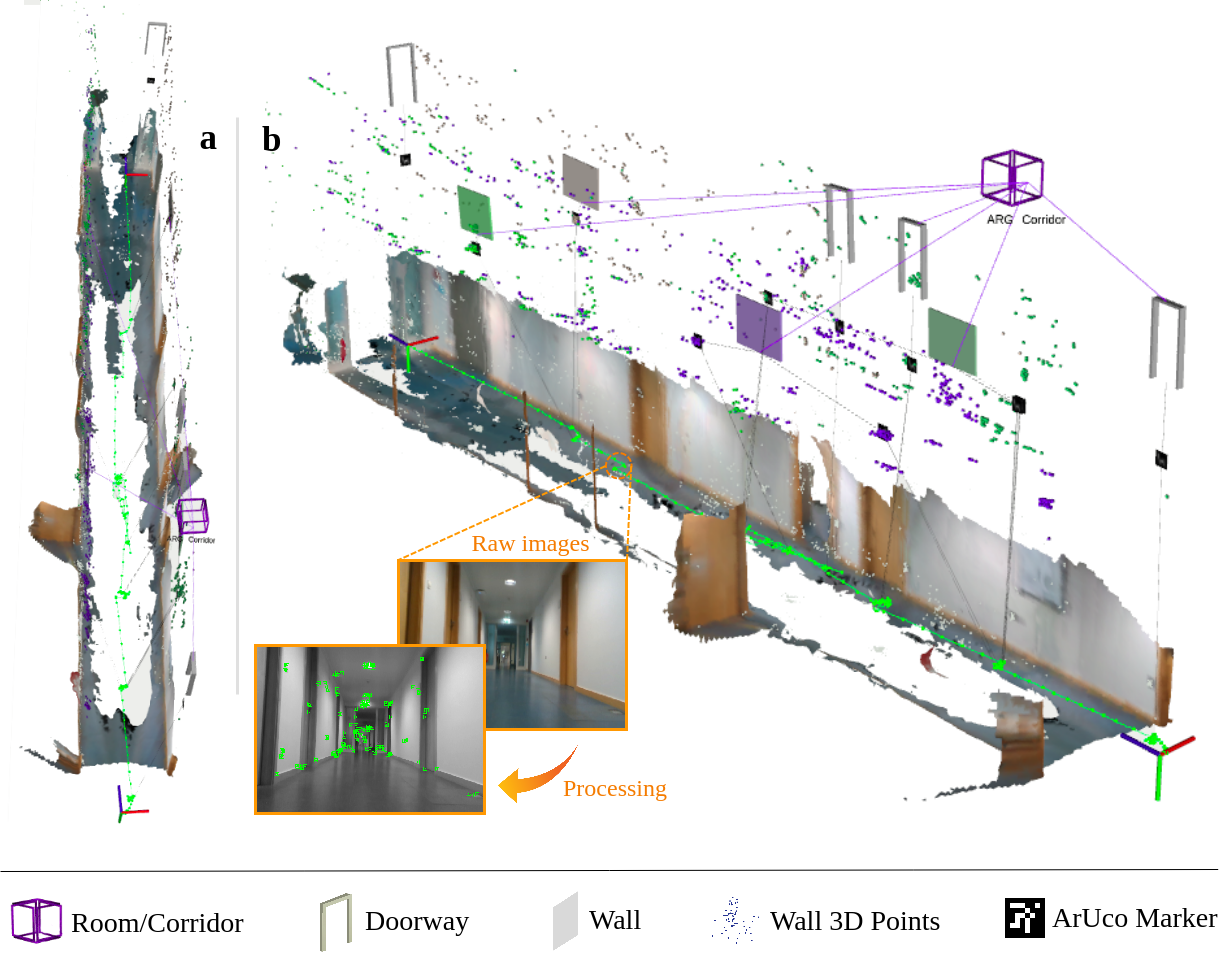
Situational Graphs (S-Graphs) merge geometric models of the environment generated by Simultaneous Localization and Mapping (SLAM) approaches with 3D scene graphs into a multi-layered jointly optimizable factor graph. As an advantage, S-Graphs not only offer a more comprehensive robotic situational awareness by combining geometric maps with diverse hierarchically organized semantic entities and their topological relationships within one graph, but they also lead to improved performance of localization and mapping on the SLAM level by exploiting semantic information. In this paper, we introduce a vision-based version of S-Graphs where a conventional \ac{VSLAM} system is used for low-level feature tracking and mapping. In addition, the framework exploits the potential of fiducial markers (both visible as well as our recently introduced transparent or fully invisible markers) to encode comprehensive information about environments and the objects within them. The markers aid in identifying and mapping structural-level semantic entities, including walls and doors in the environment, with reliable poses in the global reference, subsequently establishing meaningful associations with higher-level entities, including corridors and rooms. However, in addition to including semantic entities, the semantic and geometric constraints imposed by the fiducial markers are also utilized to improve the reconstructed map's quality and reduce localization errors. Experimental results on a real-world dataset collected using legged robots show that our framework excels in crafting a richer, multi-layered hierarchical map and enhances robot pose accuracy at the same time.
翻译:暂无翻译