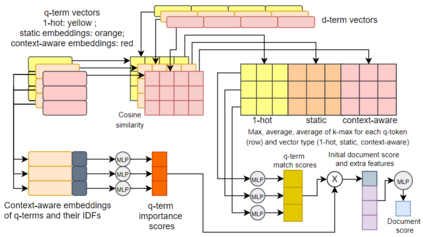
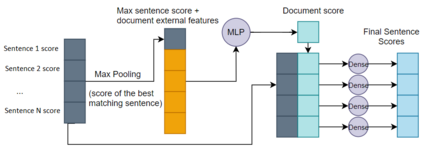
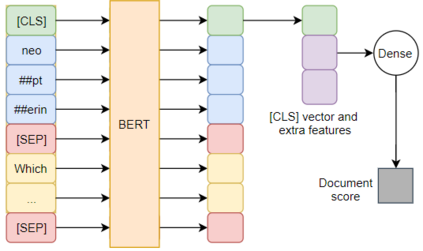
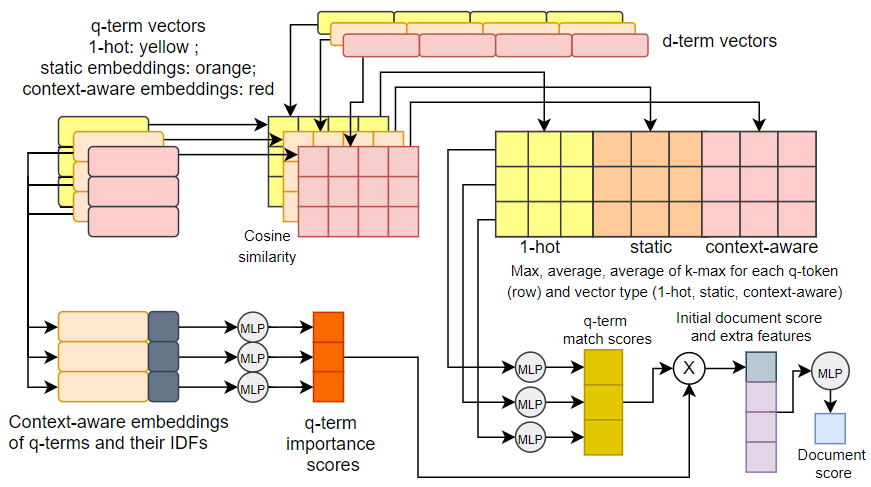
Question answering (QA) systems for large document collections typically use pipelines that (i) retrieve possibly relevant documents, (ii) re-rank them, (iii) rank paragraphs or other snippets of the top-ranked documents, and (iv) select spans of the top-ranked snippets as exact answers. Pipelines are conceptually simple, but errors propagate from one component to the next, without later components being able to revise earlier decisions. We present an architecture for joint document and snippet ranking, the two middle stages, which leverages the intuition that relevant documents have good snippets and good snippets come from relevant documents. The architecture is general and can be used with any neural text relevance ranker. We experiment with two main instantiations of the architecture, based on POSIT-DRMM (PDRMM) and a BERT-based ranker. Experiments on biomedical data from BIOASQ show that our joint models vastly outperform the pipelines in snippet retrieval, the main goal for QA, with fewer trainable parameters, also remaining competitive in document retrieval. Furthermore, our joint PDRMM-based model is competitive with BERT-based models, despite using orders of magnitude fewer parameters. These claims are also supported by human evaluation on two test batches of BIOASQ. To test our key findings on another dataset, we modified the Natural Questions dataset so that it can also be used for document and snippet retrieval. Our joint PDRMM-based model again outperforms the corresponding pipeline in snippet retrieval on the modified Natural Questions dataset, even though it performs worse than the pipeline in document retrieval. We make our code and the modified Natural Questions dataset publicly available.
翻译:用于大型文件收集的问答系统通常使用管道:(一) 检索可能相关的文件,(二) 重新排序,(三) 将上层文档的中段或其他片段排位,(四) 选择最上层片段的跨度,作为准确的答案。管道在概念上简单,但错误从一个部分传播到下一个部分,但随后各部分无法修改先前的决定。我们展示了一个联合文件和片段排位的架构,即两个中间阶段,利用相关文件具有良好片段和好片段的直觉,(二) 重新排位,(三) 将最上层文档的中段或其他片段排位排位,(三) 排位阶,(四) 排位阶段,(四) 排位阶段,(四) 以POSIT-DRMMM(PDRMM)(PDRMM)(PD)和以BERT为主列的排位。关于生物数据数据的实验显示,我们的联合模型已大大超越了管道的管道检索, QA的主要目标,(比可保持在文件检索中) QA 。此外,尽管我们使用了比数测试中,但我们的比重数据要求,但测试了我们的数据比重数据比重数据比重数据比重数据,我们的数据比比重在另一个的比重数据,我们更小。