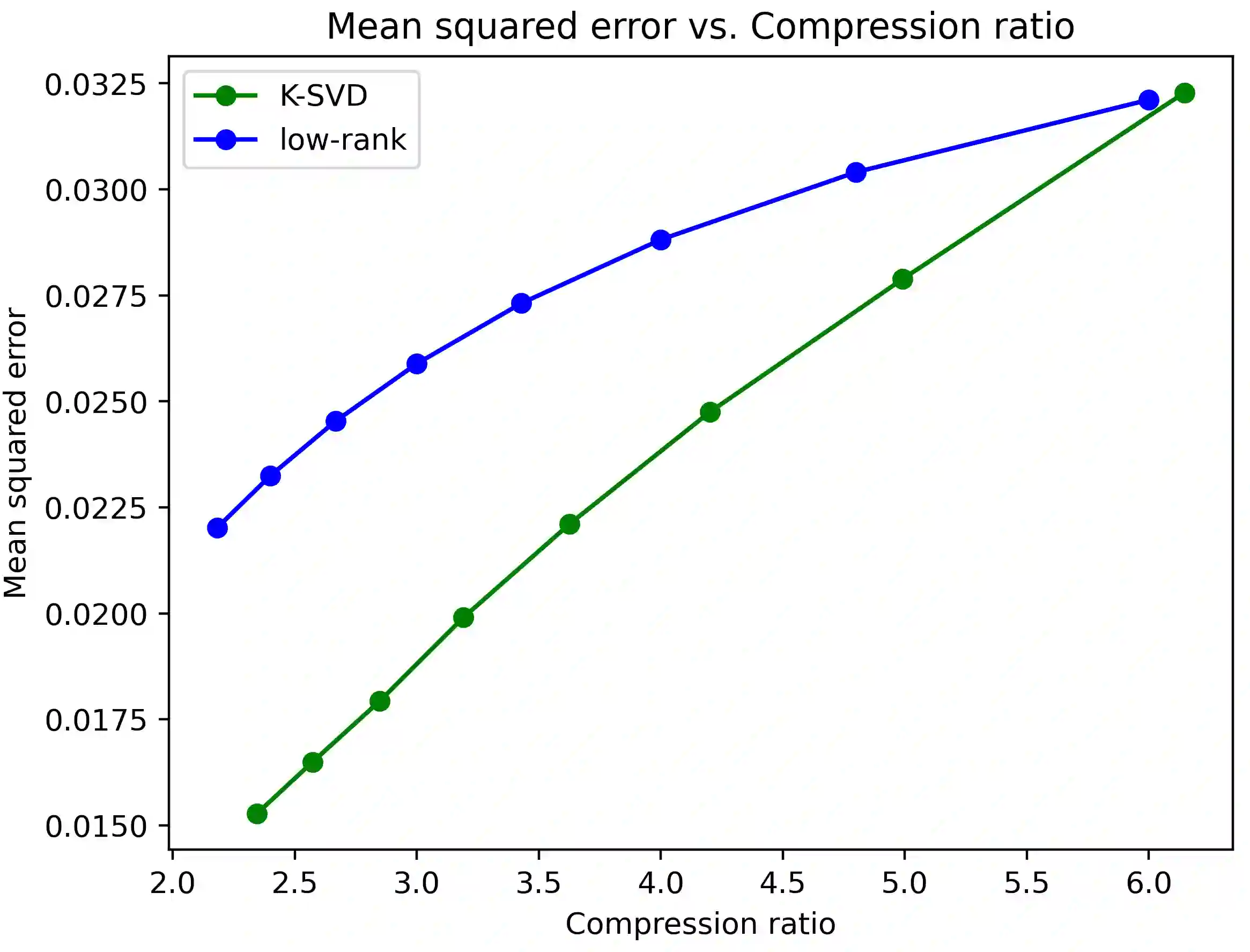
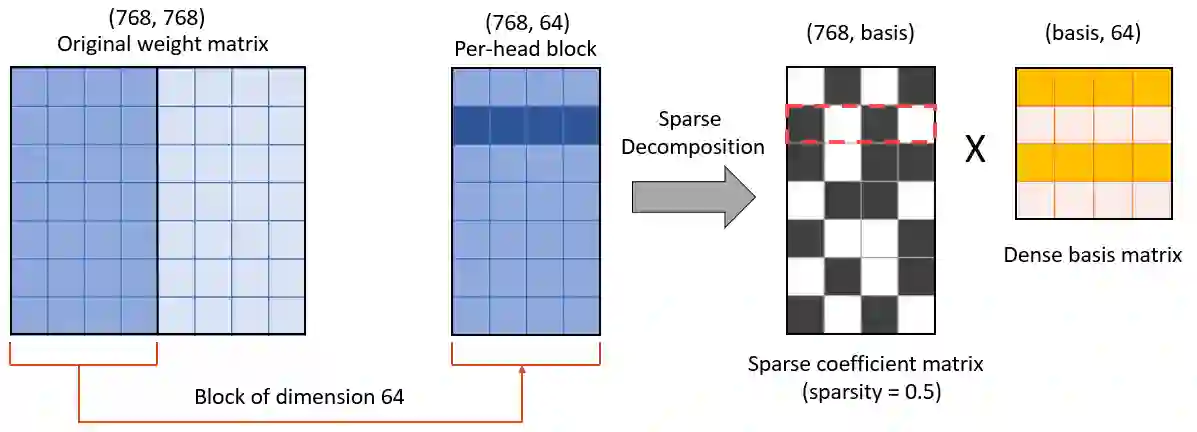
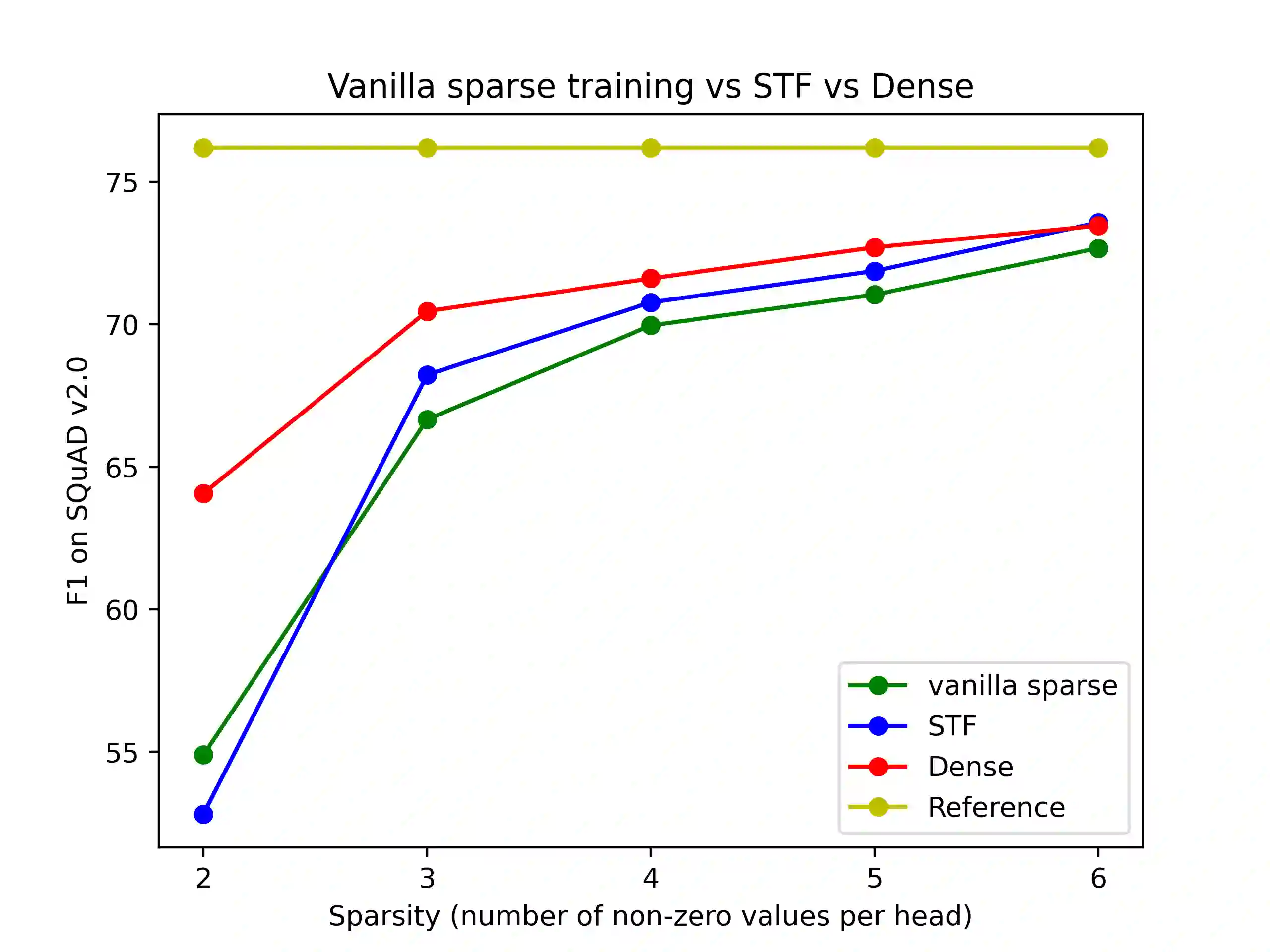
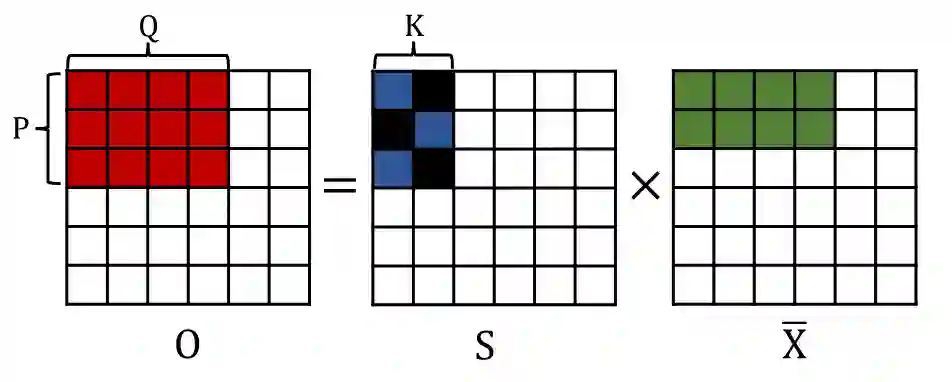With the tremendous success of large transformer models in natural language understanding, down-sizing them for cost-effective deployments has become critical. Recent studies have explored the low-rank weight factorization techniques which are efficient to train, and apply out-of-the-box to any transformer architecture. Unfortunately, the low-rank assumption tends to be over-restrictive and hinders the expressiveness of the compressed model. This paper proposes, DSFormer, a simple alternative factorization scheme which expresses a target weight matrix as the product of a small dense and a semi-structured sparse matrix. The resulting approximation is more faithful to the weight distribution in transformers and therefore achieves a stronger efficiency-accuracy trade-off. Another concern with existing factorizers is their dependence on a task-unaware initialization step which degrades the accuracy of the resulting model. DSFormer addresses this issue through a novel Straight-Through Factorizer (STF) algorithm that jointly learns all the weight factorizations to directly maximize the final task accuracy. Extensive experiments on multiple natural language understanding benchmarks demonstrate that DSFormer obtains up to 40% better compression than the state-of-the-art low-rank factorizers, leading semi-structured sparsity baselines and popular knowledge distillation approaches. Our approach is also orthogonal to mainstream compressors and offers up to 50% additional compression when added to popular distilled, layer-shared and quantized transformers. We empirically evaluate the benefits of STF over conventional optimization practices.
翻译:暂无翻译