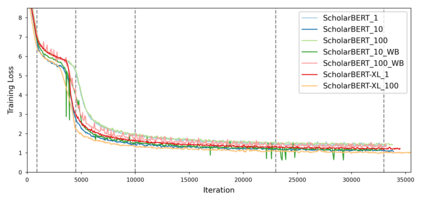
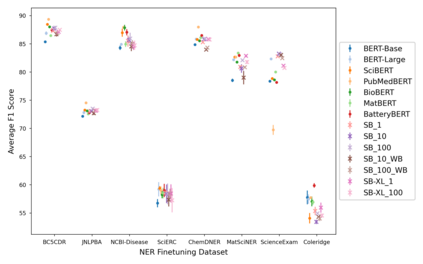
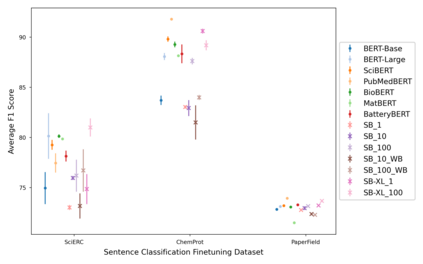
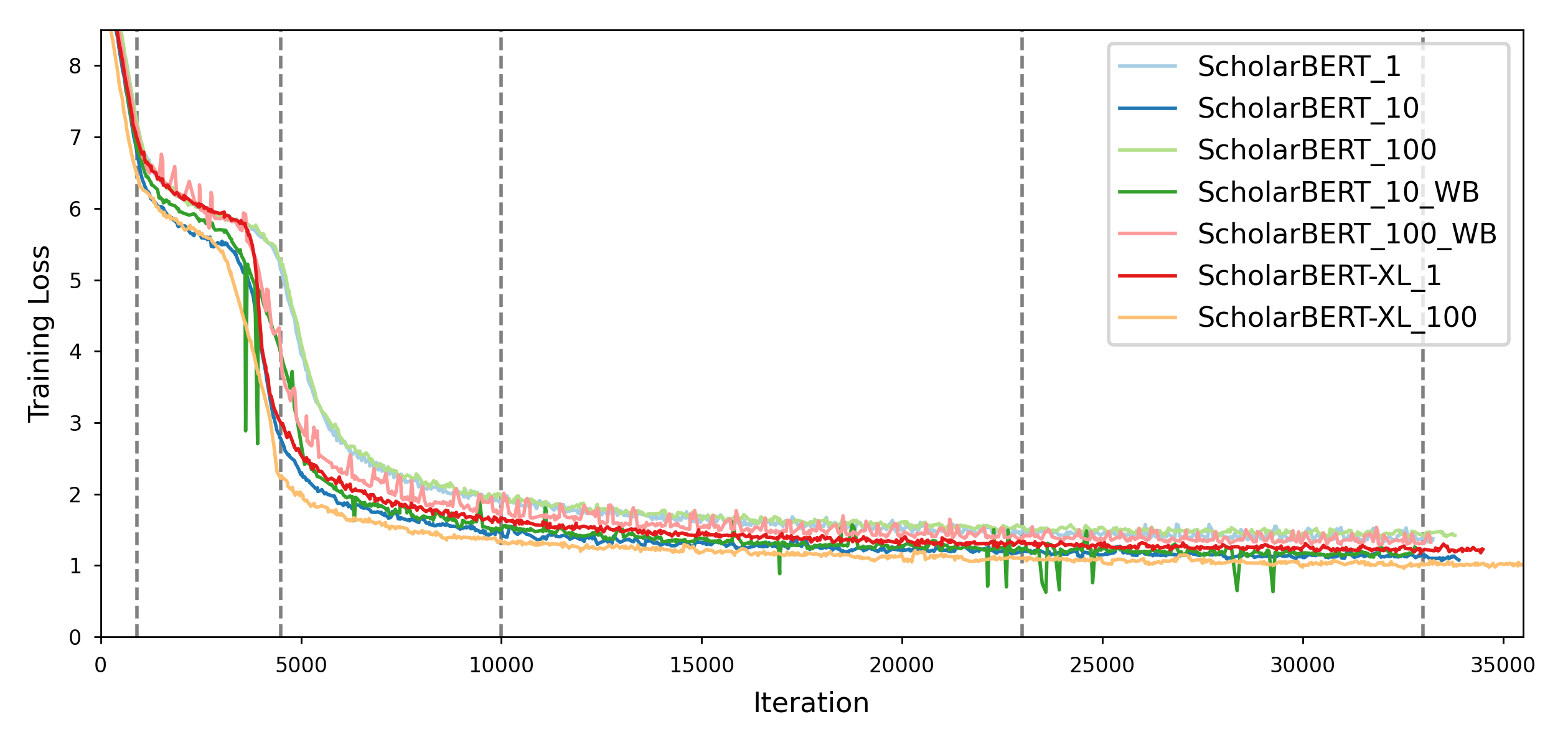
Transformer-based masked language models trained on general corpora, such as BERT and RoBERTa, have shown impressive performance on various downstream tasks. Increasingly, researchers are "finetuning" these models to improve performance on domain-specific tasks. Here, we report a broad study in which we applied 14 transformer-based models to 11 scientific tasks in order to evaluate how downstream performance is affected by changes along various dimensions (e.g., training data, model size, pretraining time, finetuning length). In this process, we created the largest and most diverse scientific language model to date, ScholarBERT, by training a 770M-parameter BERT model on an 221B token scientific literature dataset spanning many disciplines. Counterintuitively, our evaluation of the 14 BERT-based models (seven versions of ScholarBERT, five science-specific large language models from the literature, BERT-Base, and BERT-Large) reveals little difference in performance across the 11 science-focused tasks, despite major differences in model size and training data. We argue that our results establish an upper bound for the performance achievable with BERT-based architectures on tasks from the scientific domain.
翻译:根据一般公司(如BERT和ROBERTA)培训的基于变压器的蒙面语言模型显示了在各种下游任务方面的令人印象深刻的业绩。研究人员越来越多地“改进”这些模型,以改进具体领域任务的业绩。在这里,我们报告了一项广泛的研究,我们将14个基于变压器的模型应用于11项科学任务,以便评估下游业绩如何受到不同层面变化(如培训数据、模型规模、培训前时间、微调长度)的影响。在这个过程中,我们创建了迄今为止最大和最多样化的科学语言模型,即ScharnicBERT, 培训了770M参数的BERT模型, 培训了221B号象征性科学文献数据集,涵盖多个学科。反直观地说,我们对14个基于BERT的模型(7个版本的学者BERT,5个来自文献、BERT-B和BERT-Large)的评估显示,在11项以科学为重点的任务中的绩效差异很小,尽管模型规模和培训数据存在重大差异。我们认为,我们的成果为与基于科学领域的建筑的可实现的绩效建立了上限。