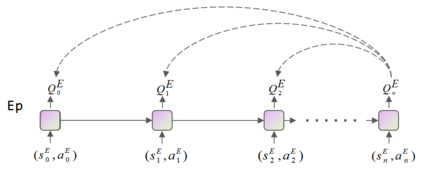
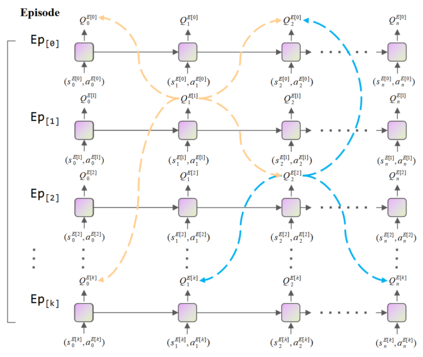
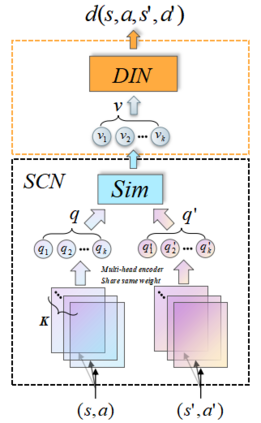
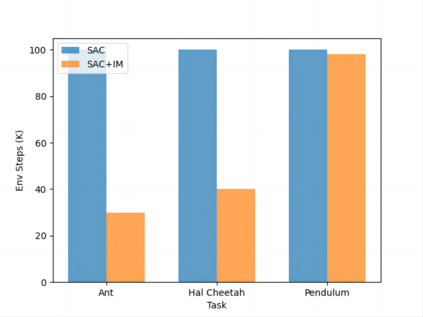
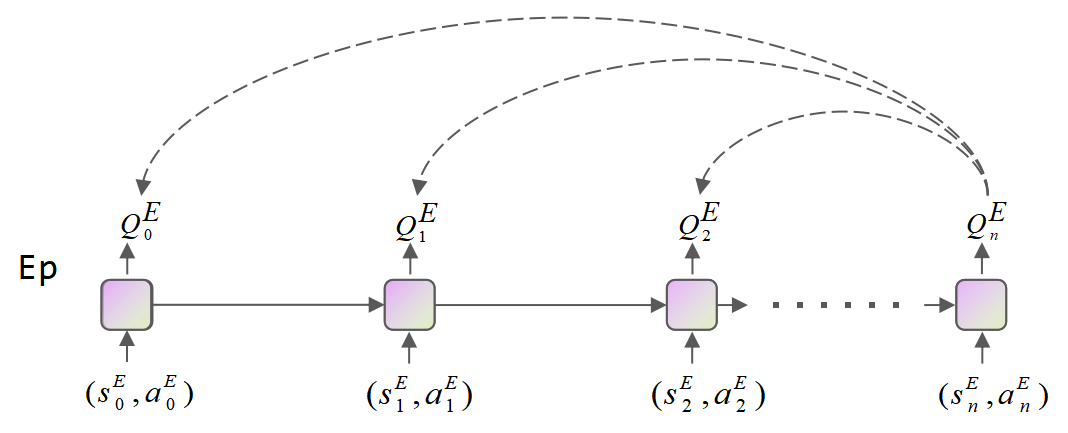
Reinforcement learning (RL) algorithms face the challenge of limited data efficiency, particularly when dealing with high-dimensional state spaces and large-scale problems. Most RL methods often rely solely on state transition information within the same episode when updating the agent's Critic, which can lead to low data efficiency and sub-optimal training time consumption. Inspired by human-like analogical reasoning abilities, we introduce a novel mesh information propagation mechanism, termed the 'Imagination Mechanism (IM)', designed to significantly enhance the data efficiency of RL algorithms. Specifically, IM enables information generated by a single sample to be effectively broadcasted to different states, instead of simply transmitting in the same episode and it allows the model to better understand the interdependencies between states and learn scarce sample information more efficiently. To promote versatility, we extend the imagination mechanism to function as a plug-and-play module that can be seamlessly and fluidly integrated into other widely adopted RL models. Our experiments demonstrate that Imagination mechanism consistently boosts four mainstream SOTA RL-algorithms, such as SAC, PPO, DDPG, and DQN, by a considerable margin, ultimately leading to superior performance than before across various tasks. For access to our code and data, please visit https://github.com/Zero-coder/FECAM.
翻译:暂无翻译