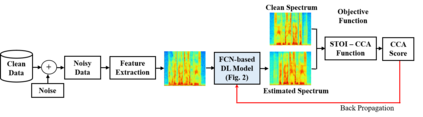
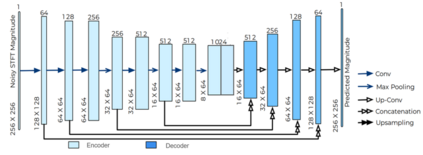
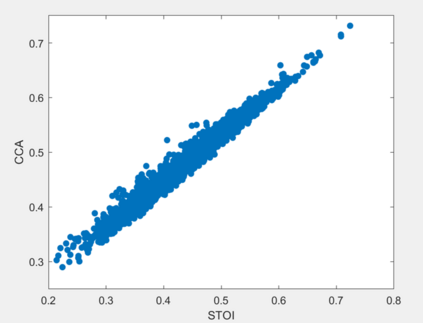
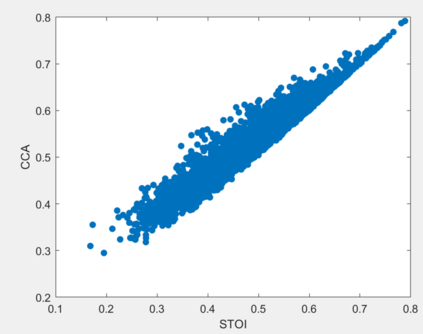
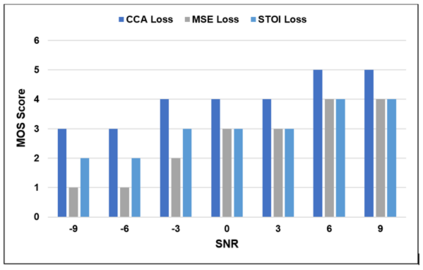
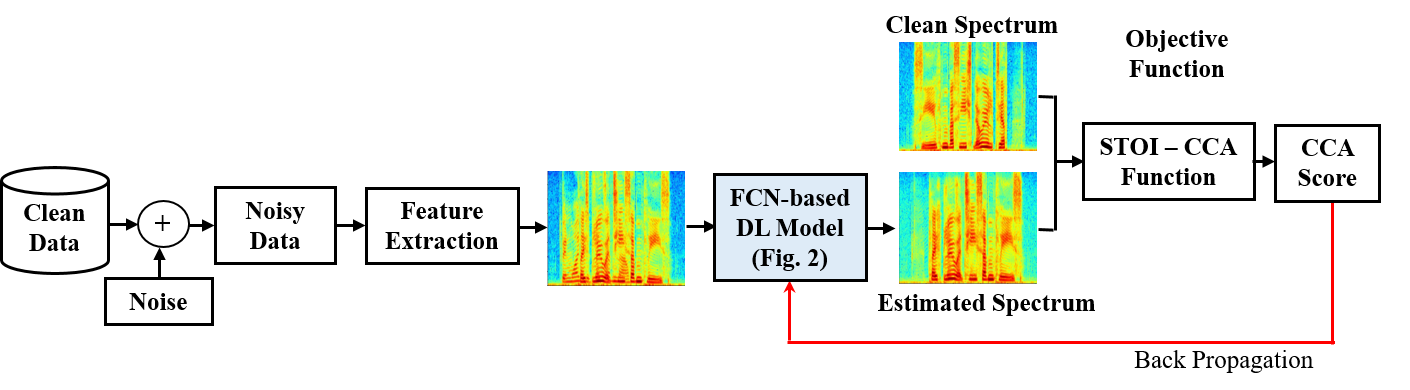
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.
翻译:在吵闹的环境下,目前基于深层学习(DL)的增强语音智能的方法往往经过培训,以尽量减少无噪音言论和强化语音信号之间的特长距离。尽管这些方法提高了语言质量,但在日常的吵闹环境中并没有达到必要的语音智能水平。最近开发了以智能为导向的损失功能,以培训DL的强化语音方法。在这里,我们首次开发了基于新颖的基于光学的I-O损失相关功能,以更有效地培训DL算法。具体地说,我们提出了一个基于光学的短期目标智能(CC-STOI)成本功能,用于培训完全革命性神经网络模型。我们进行了比较模拟实验,以表明我们基于CC-STOI的语音增强框架,与经过常规远程和基于STOI的损失功能培训的、符合现状的DL模型相形形形形形形形形形色色,同时使用客观和主观的评价措施来评估隐形的发言者和噪音案例。正在进行的未来工作正在评估设计稳健的听力定位技术的拟议设计方法。