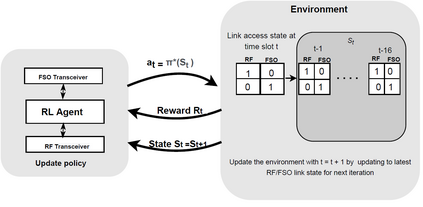
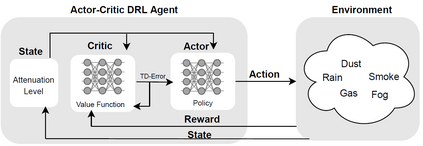
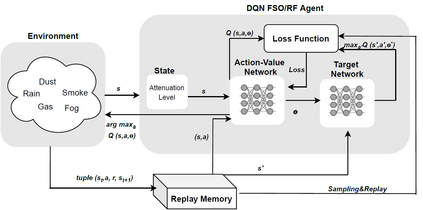
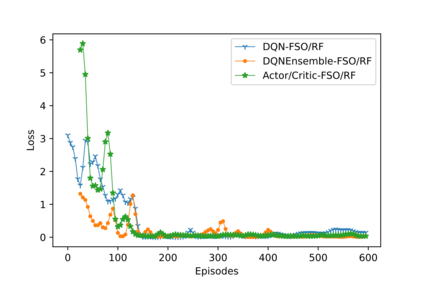
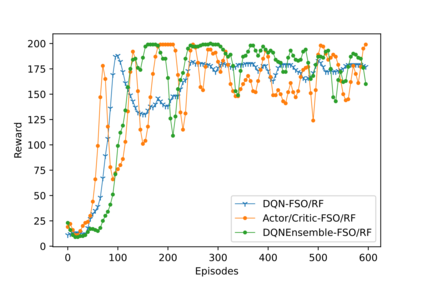
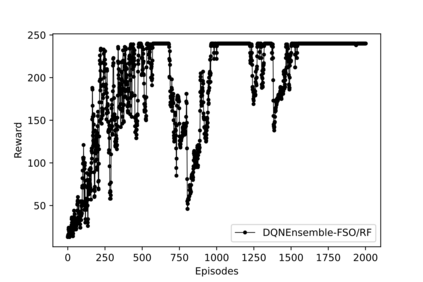
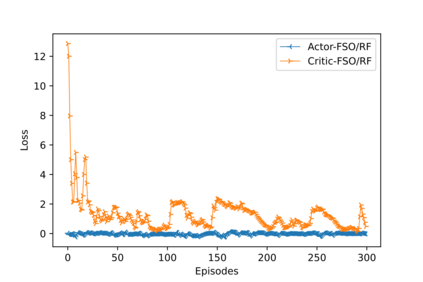
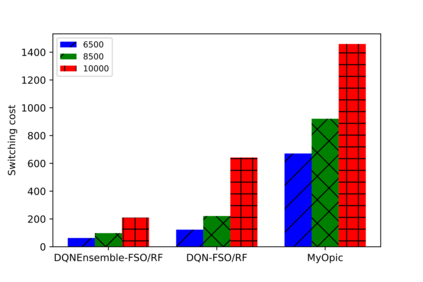
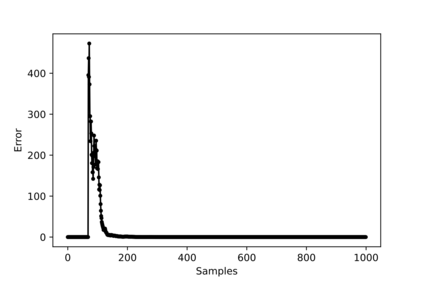
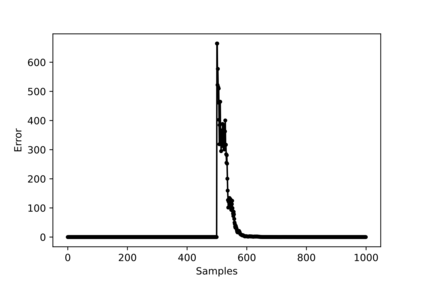
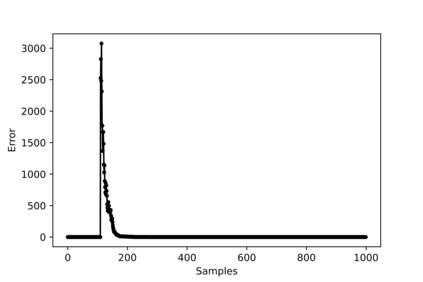
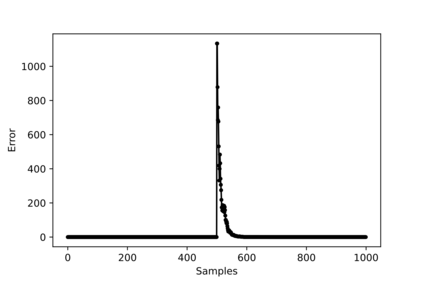
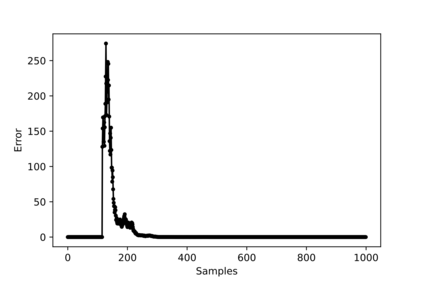
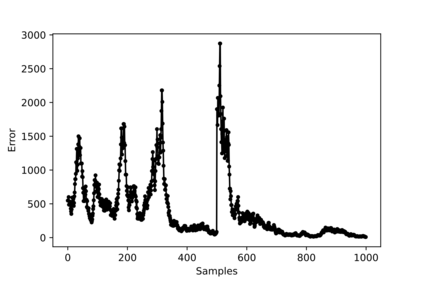
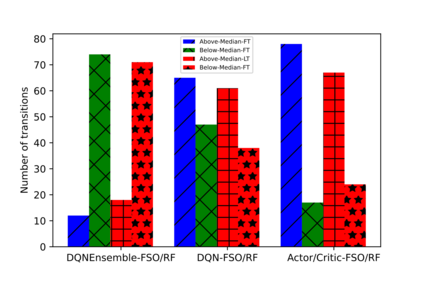
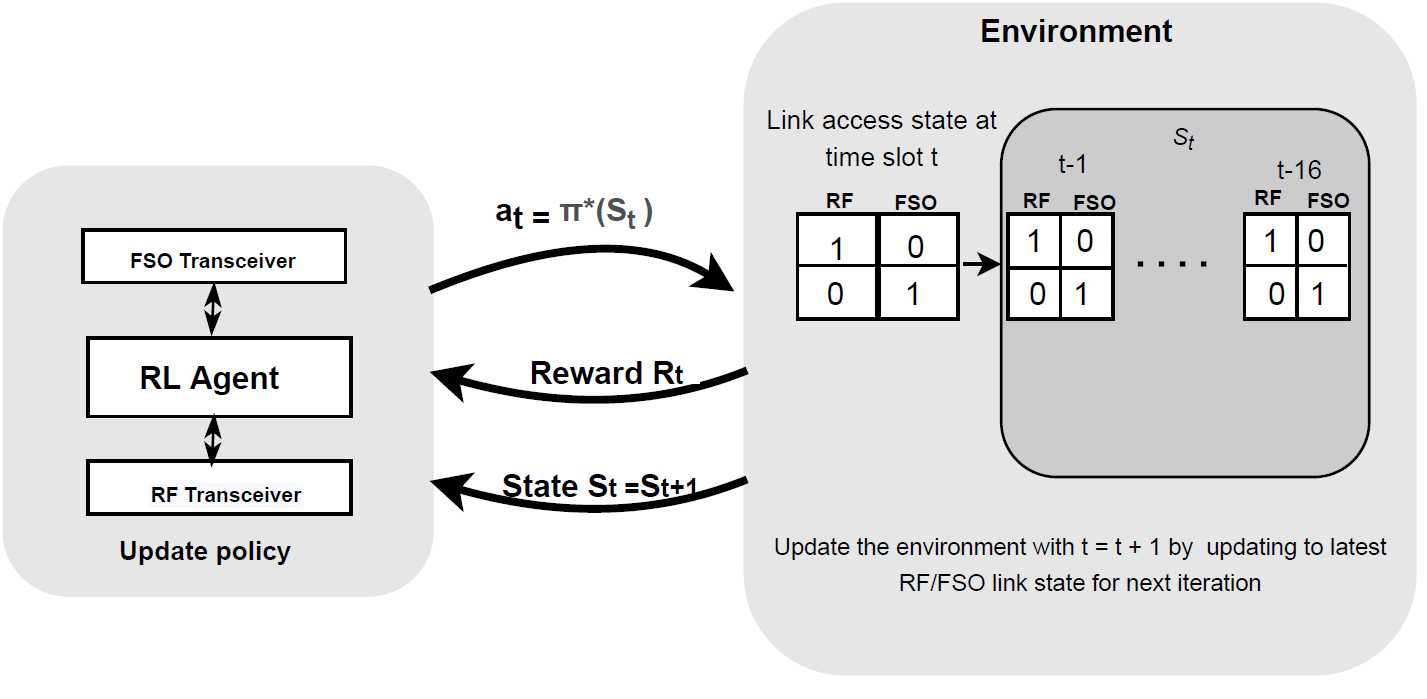
Hybrid FSO/RF system requires an efficient FSO and RF link switching mechanism to improve the system capacity by realizing the complementary benefits of both the links. The dynamics of network conditions, such as fog, dust, and sand storms compound the link switching problem and control complexity. To address this problem, we initiate the study of deep reinforcement learning (DRL) for link switching of hybrid FSO/RF systems. Specifically, in this work, we focus on actor-critic called Actor/Critic-FSO/RF and Deep-Q network (DQN) called DQN-FSO/RF for FSO/RF link switching under atmospheric turbulences. To formulate the problem, we define the state, action, and reward function of a hybrid FSO/RF system. DQN-FSO/RF frequently updates the deployed policy that interacts with the environment in a hybrid FSO/RF system, resulting in high switching costs. To overcome this, we lift this problem to ensemble consensus-based representation learning for deep reinforcement called DQNEnsemble-FSO/RF. The proposed novel DQNEnsemble-FSO/RF DRL approach uses consensus learned features representations based on an ensemble of asynchronous threads to update the deployed policy. Experimental results corroborate that the proposed DQNEnsemble-FSO/RF's consensus-learned features switching achieves better performance than Actor/Critic-FSO/RF, DQN-FSO/RF, and MyOpic for FSO/RF link switching while keeping the switching cost significantly low.
翻译:为了解决这一问题,我们开始研究关于将FSO/RF混合系统连接起来的深层强化学习(DRL),具体地说,在这项工作中,我们侧重于称为Actor/Critic-FSO/RF/RF和Diep-Q(DQN)的行为体-cread-commission-resmation(DQNN-FSO/RF)网络(DQN-FRS/RF),称为FSO/RF在大气动荡下转换为FSO/RF。为了解决问题,我们定义了FSO/RF混合系统的现状、行动和奖励功能。DQNEF-FSO/RF经常更新在混合FSO/RF系统中与环境互动的部署政策,导致高昂的转换成本。要克服这个问题,我们把这一问题提升为基于共同共识的深度强化学习,称为DQNESB-FSO/RF。拟议的DQ-RFSO-SO-SOL-SOLSO的升级化成果,同时学习基于SO-RFSO-RODRBRMMA的升级的SBRMRMRMRMRMMMMMRMRMRMRMRMM的升级成果。