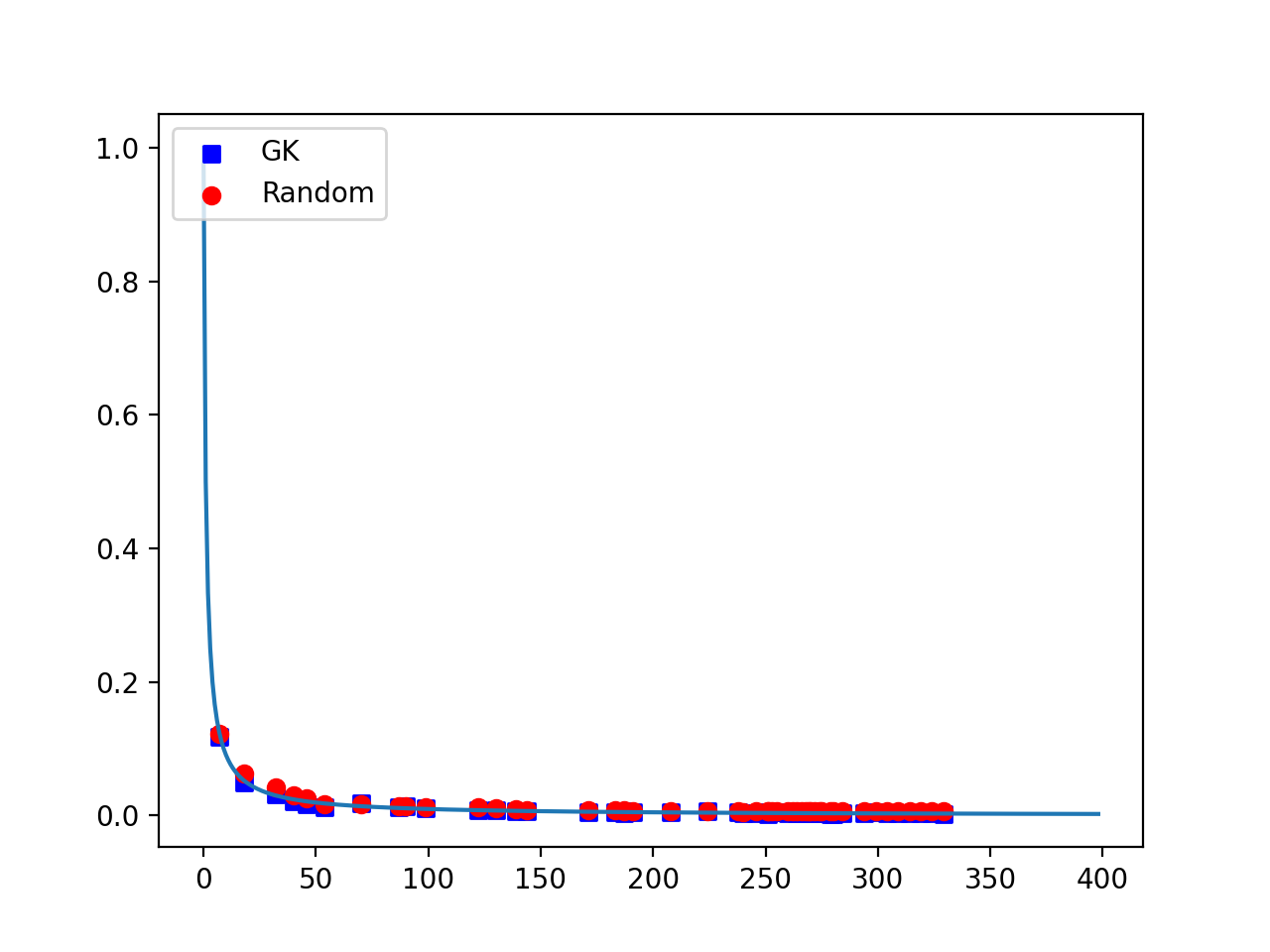
In recent years, gradient boosted decision trees have become popular in building robust machine learning models on big data. The primary technique that has enabled these algorithms success has been distributing the computation while building the decision trees. A distributed decision tree building, in turn, has been enabled by building quantiles of the big datasets and choosing the candidate split points from these quantile sets. In XGBoost, for instance, a sophisticated quantile building algorithm is employed to identify the candidate split points for the decision trees. This method is often projected to yield better results when the computation is distributed. In this paper, we dispel the notion that these methods provide more accurate and scalable methods for building decision trees in a distributed manner. In a significant contribution, we show theoretically and empirically that choosing the split points uniformly at random provides the same or even better performance in terms of accuracy and computational efficiency. Hence, a simple random selection of points suffices for decision tree building compared to more sophisticated methods.
翻译:近年来,梯度推动决策树在建立关于大数据的稳健机器学习模型方面变得很受欢迎。使得这些算法成功的主要技术一直是在建设决策树的同时分配计算方法。分布式决策树建筑反过来通过建立大数据集的四分位和从这些四分位组中选择候选人的分点而得以实现。例如,在 XGBoost 中,采用了复杂的量级建筑算法来确定决策树的候选人分点。在分配计算时,这种方法往往预测会产生更好的结果。在本文中,我们消除了这些方法为以分布式方式建设决策树提供了更准确和可缩放的方法的观念。我们做出了重要贡献,从理论上和实验上表明,随机选择分点的做法在准确性和计算效率方面提供了相同甚至更好的表现。因此,简单随机选择点足以使决策树的建设与更精密的方法相比更符合。