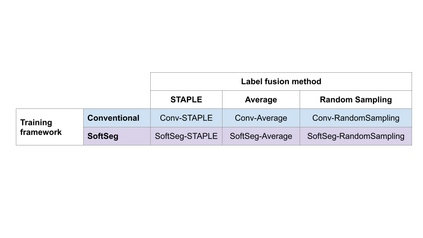
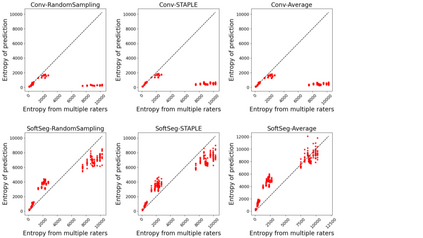
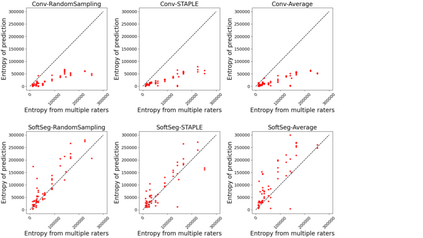
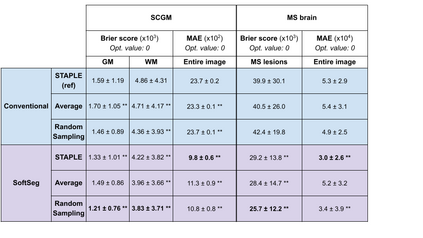
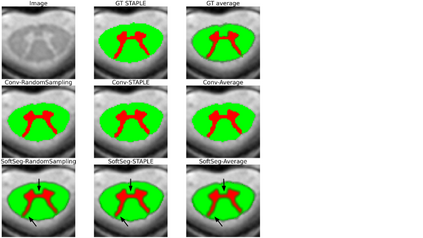
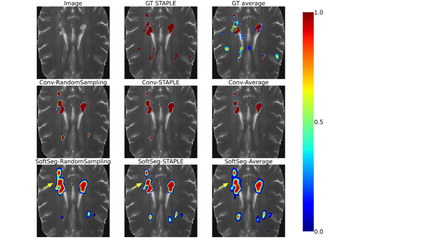
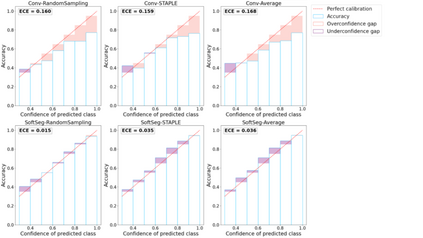
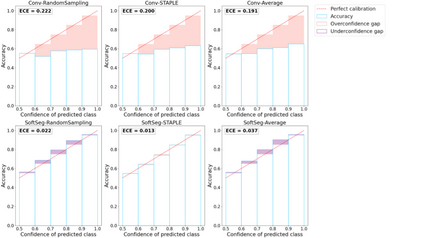
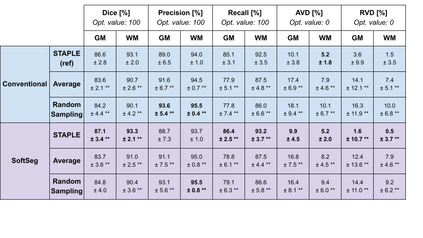
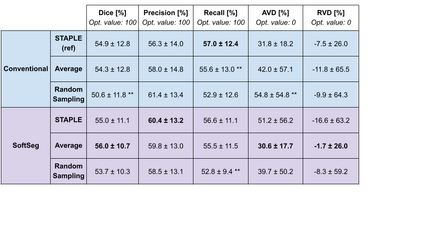
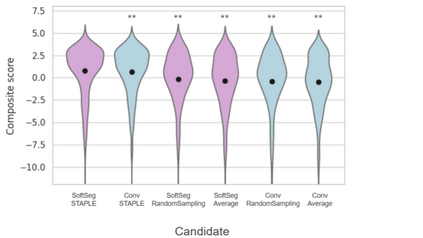
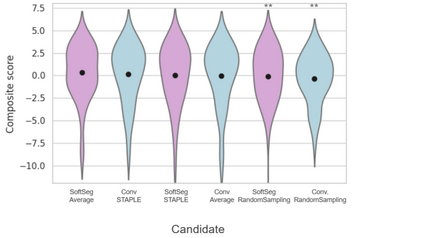
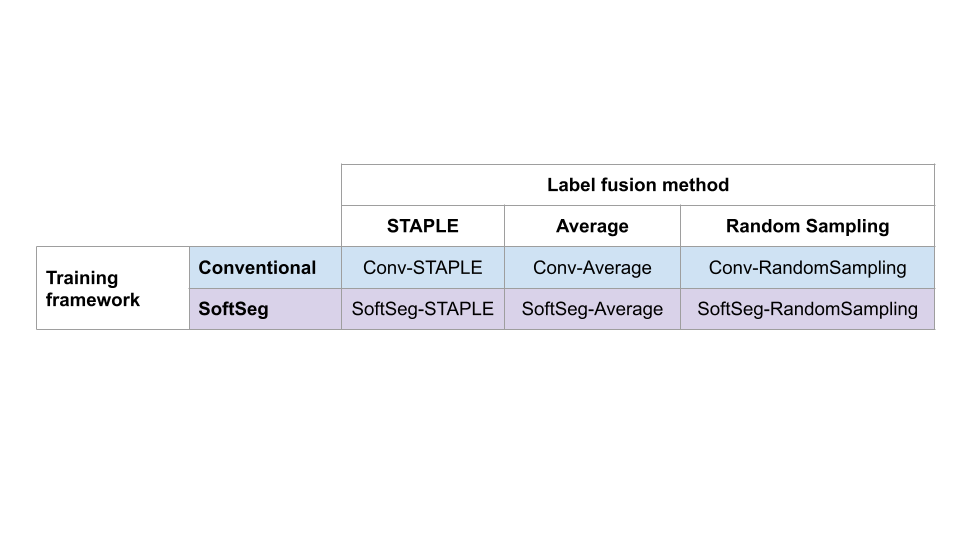
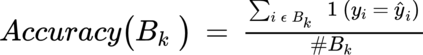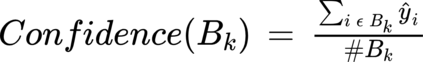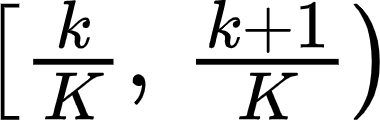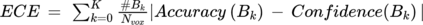Medical tasks are prone to inter-rater variability due to multiple factors such as image quality, professional experience and training, or guideline clarity. Training deep learning networks with annotations from multiple raters is a common practice that mitigates the model's bias towards a single expert. Reliable models generating calibrated outputs and reflecting the inter-rater disagreement are key to the integration of artificial intelligence in clinical practice. Various methods exist to take into account different expert labels. We focus on comparing three label fusion methods: STAPLE, average of the rater's segmentation, and random sampling each rater's segmentation during training. Each label fusion method is studied using the conventional training framework or the recently published SoftSeg framework that limits information loss by treating the segmentation task as a regression. Our results, across 10 data splittings on two public datasets, indicate that SoftSeg models, regardless of the ground truth fusion method, had better calibration and preservation of the inter-rater rater variability compared with their conventional counterparts without impacting the segmentation performance. Conventional models, i.e., trained with a Dice loss, with binary inputs, and sigmoid/softmax final activate, were overconfident and underestimated the uncertainty associated with inter-rater variability. Conversely, fusing labels by averaging with the SoftSeg framework led to underconfident outputs and overestimation of the rater disagreement. In terms of segmentation performance, the best label fusion method was different for the two datasets studied, indicating this parameter might be task-dependent. However, SoftSeg had segmentation performance systematically superior or equal to the conventionally trained models and had the best calibration and preservation of the inter-rater variability.
翻译:由于图像质量、专业经验、培训或准则清晰度等多种因素,医疗任务容易发生跨行业变化。培训深层次学习网络,加上多发率员的说明,是减少模型对单一专家偏差的常见做法。可靠的模型产生校准产出并反映跨行业的分歧,是将人工智能纳入临床实践的关键。有各种方法可以考虑不同的专家标签。我们侧重于比较三个标签混和方法:STAPLE, 比率分解的平均值, 和在培训期间随机抽取每个调价员的分解。每个标签混合方法都是使用常规培训框架或最近公布的软塞框架来研究,通过将分解任务作为回归来限制信息损失。我们的结果,在两个公共数据集中横跨10个数据,显示SftSeget模型,不论地面真相保存方法如何,都更精确和保存了跨行业的调率变量,而没有影响分解性绩效。常规模型,例如,用Dicese值分解法进行最终的测试,Segreal-defrical Sliction Slievation Serview Sildal ex ex ex ex Extrading 和Sildlievildal dal dislate delviewdal dal exmlation 和Sildal dolviolviolviolviewds, 和Sildal disldaldaldaldaldal ords ordaldaldaldald) 和Suldal 等模型可能比比比比比, 。 。Slidaldald 。 。 。 。 。 和Slidaldaldaldaldaldaldaldaldal- 和Suldaldaldaldaldaldaldaldaldal- 和Suldaldaldaldaldaldaldaldaldaldal- 和Sildal- 等 和Sdeal- 和Sladal 和Sladald 。Sladaldaldaldaldaldaldaldaldaldaldaldal 和Sladaldal-