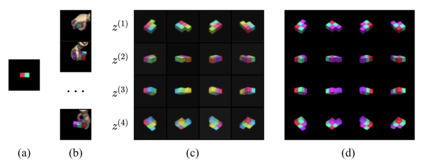
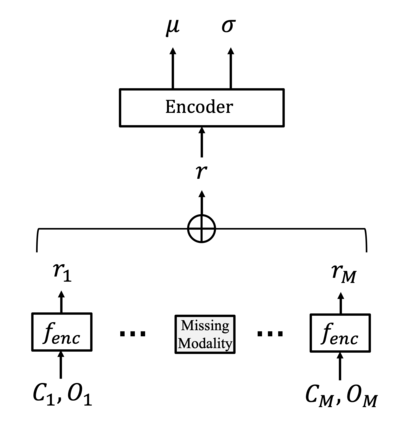
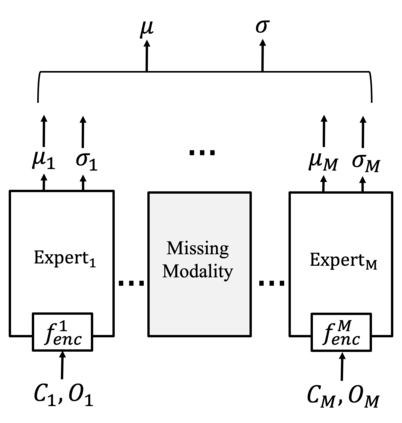
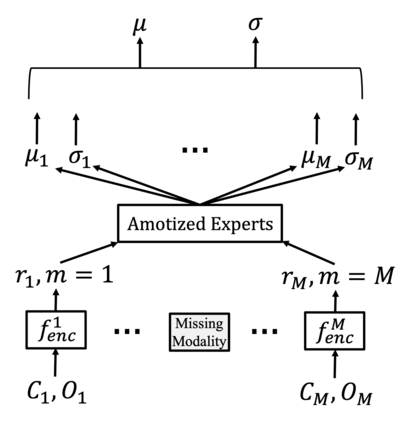
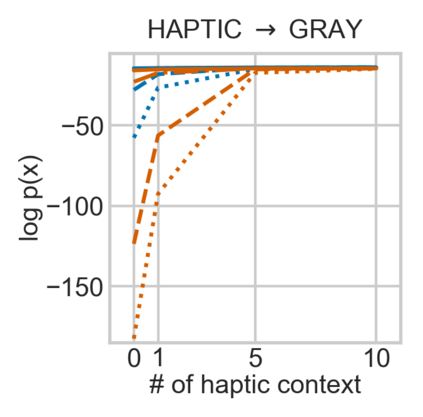
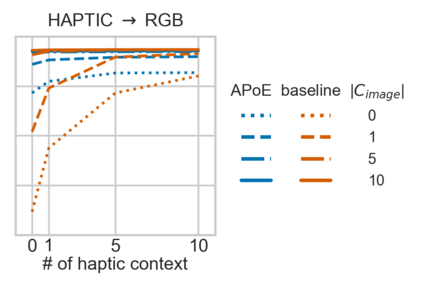
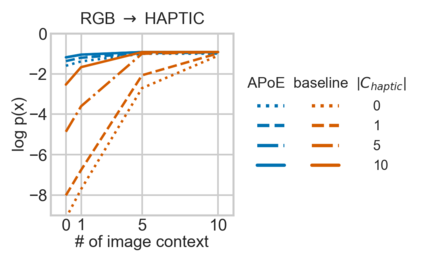
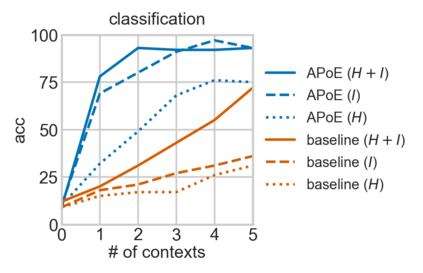
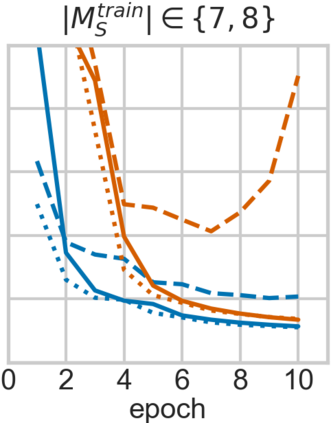
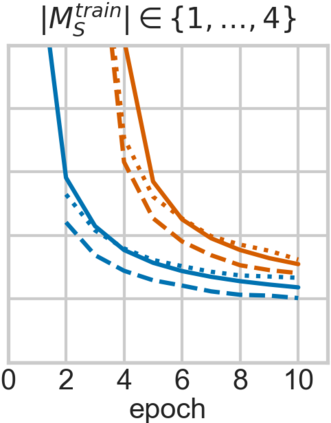
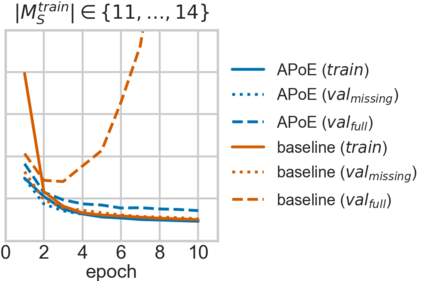
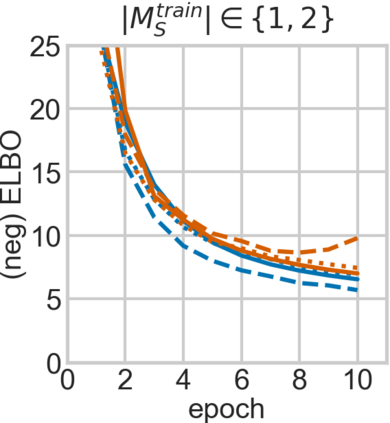
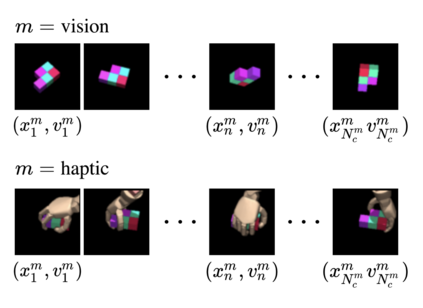
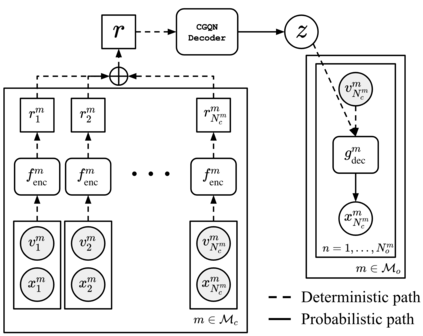
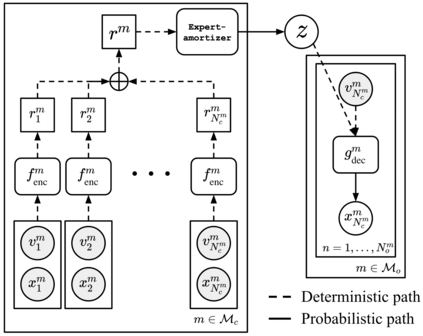
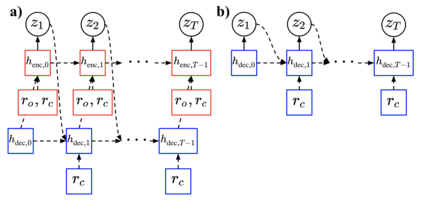
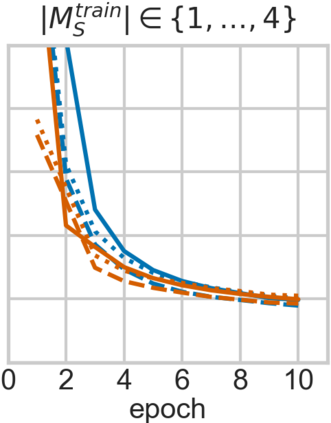
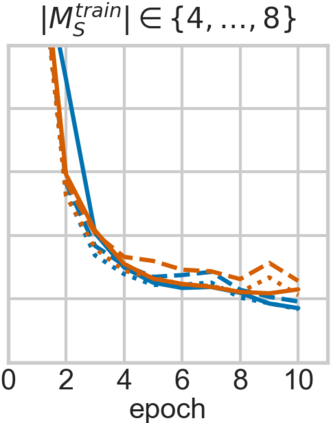
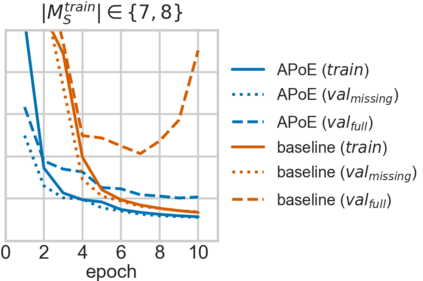
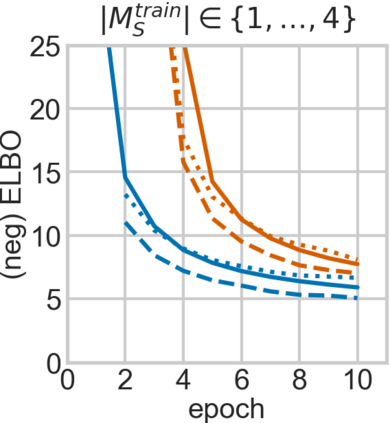
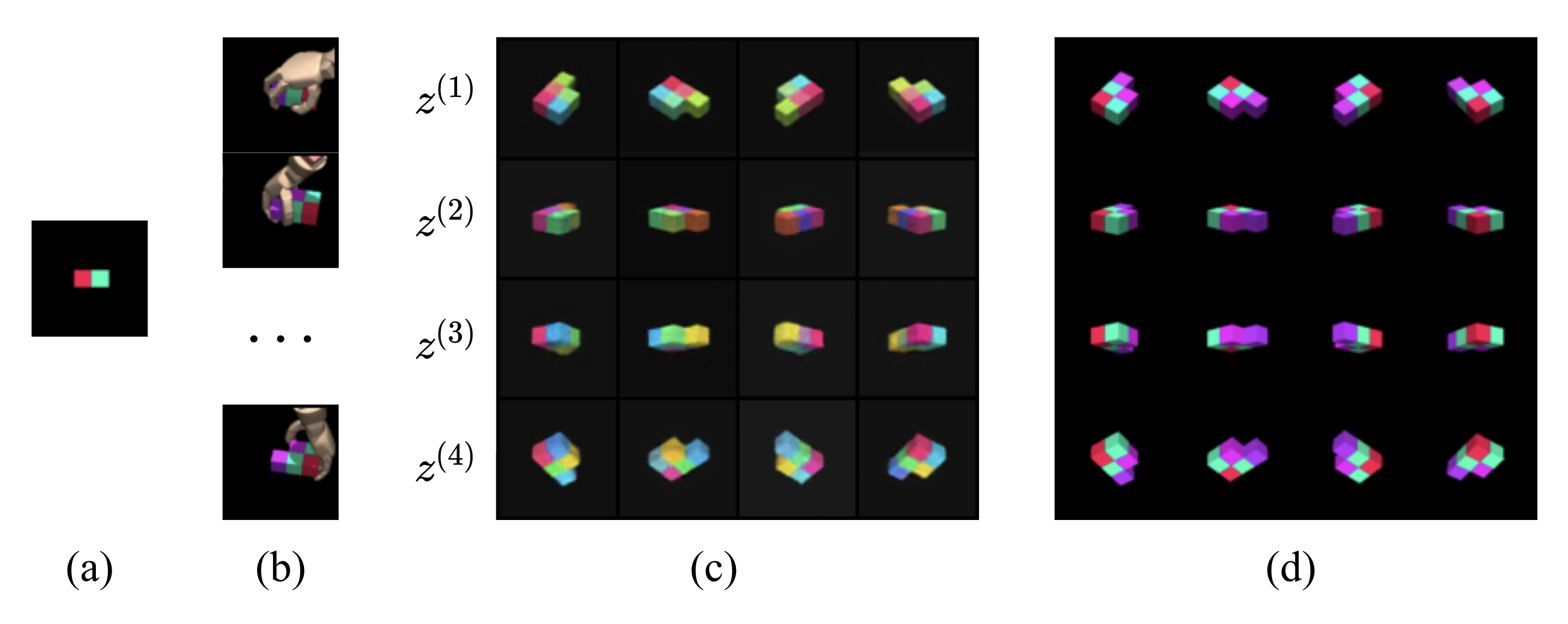
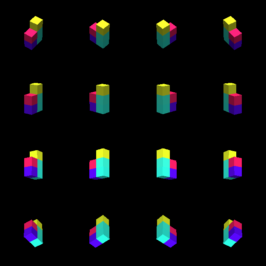For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine multisensory cues from numerous trials, e.g., by looking at and touching objects. Despite its importance, multisensory 3D scene representation learning has received less attention compared to the unimodal setting. In this paper, we propose the Generative Multisensory Network (GMN) for learning latent representations of 3D scenes which are partially observable through multiple sensory modalities. We also introduce a novel method, called the Amortized Product-of-Experts, to improve the computational efficiency and the robustness to unseen combinations of modalities at test time. Experimental results demonstrate that the proposed model can efficiently infer robust modality-invariant 3D-scene representations from arbitrary combinations of modalities and perform accurate cross-modal generation. To perform this exploration, we also develop the Multisensory Embodied 3D-Scene Environment (MESE).
翻译:为了推断它们所居住的3D基本物理世界的隐含物剂,它们应该有效地结合许多试验的多感知信号,例如,通过查看和触摸物体。尽管多感知3D场表象学习很重要,但与单一模式环境相比,它受到的关注较少。在本文件中,我们建议“创能多感网络”用于了解3D场景的潜在表现,这些场景通过多种感知模式部分可见。我们还引入了一种新颖的方法,称为“集成产品专家”,以提高计算效率和在试验时间对各种模式的无形组合的稳健性。实验结果表明,拟议的模型能够从任意组合模式中有效地推断出稳健的3D模式-变异3D色,并进行准确的跨模式的一代。为了进行这一探索,我们还开发了“多感知3D-显性环境”(MESE)。