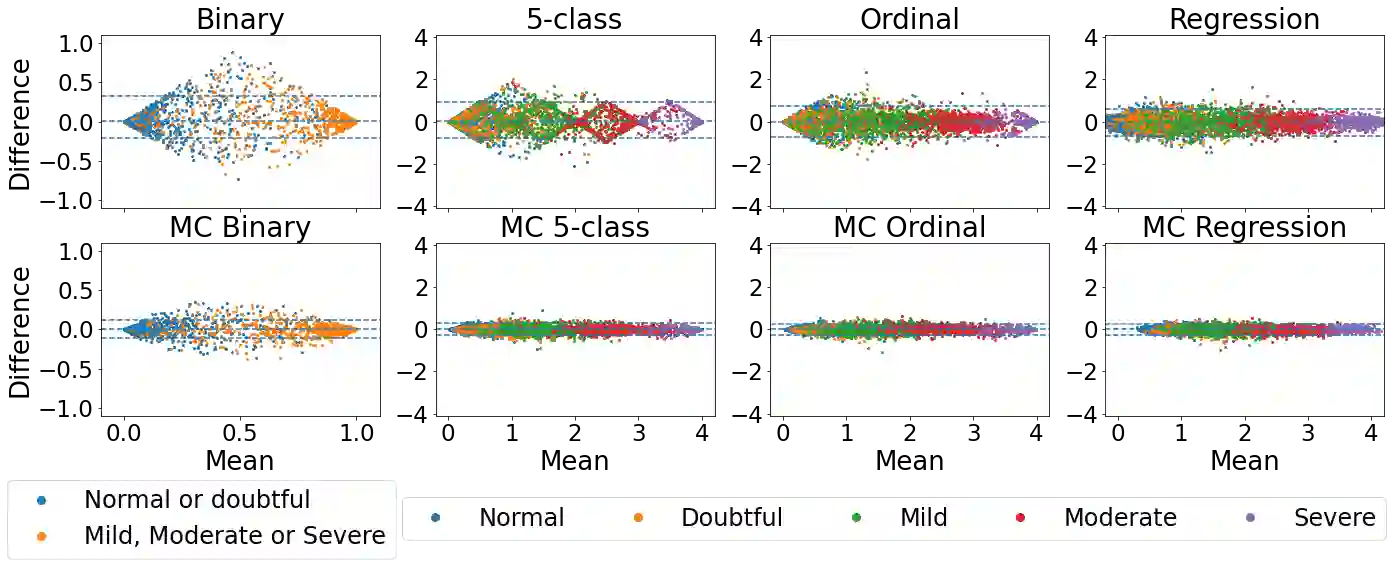
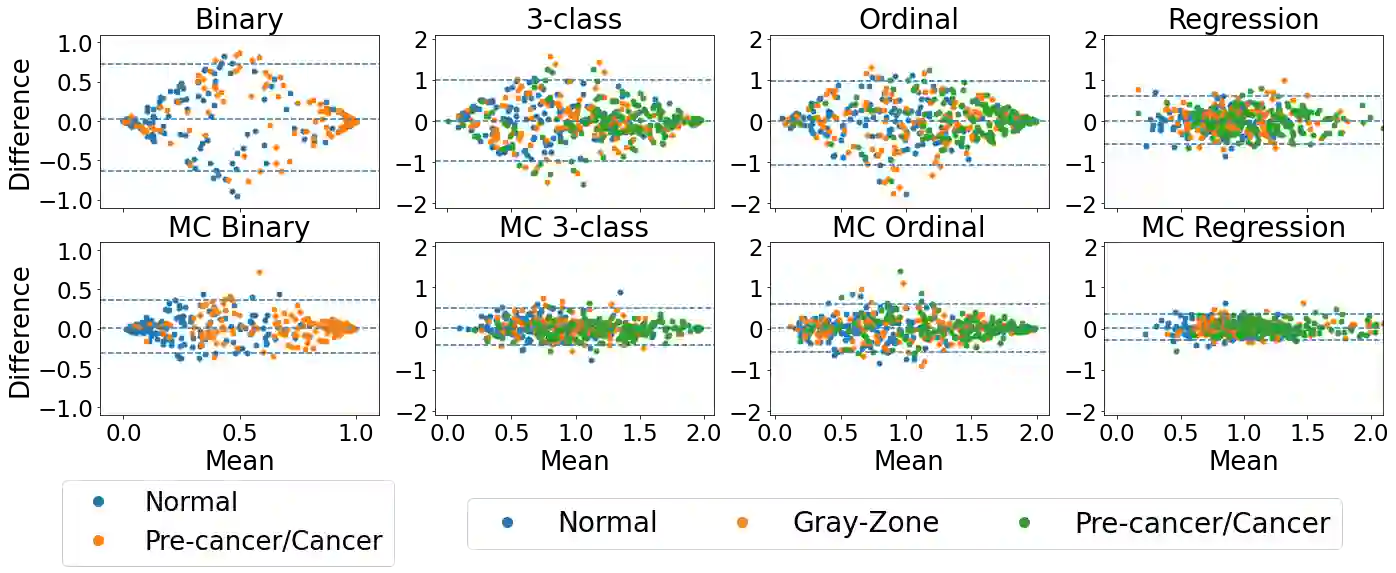
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Repeatability is a key attribute of model robustness. Repeatable models output predictions with low variation during independent tests carried out under similar conditions. During model development and evaluation, much attention is given to classification performance while model repeatability is rarely assessed, leading to the development of models that are unusable in clinical practice. In this work, we evaluate the repeatability of four model types (binary classification, multi-class classification, ordinal classification, and regression) on images that were acquired from the same patient during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on four medical image classification tasks from public and private datasets: knee osteoarthritis, cervical cancer screening, breast density estimation, and retinopathy of prematurity. Repeatability is measured and compared on ResNet and DenseNet architectures. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95\% limits of agreement by 16% points and of the disagreement rate by 7% points. The classification accuracy improved in most settings along with the repeatability. Our results suggest that beyond about 20 Monte Carlo iterations, there is no further gain in repeatability. In addition to the higher test-retest agreement, Monte Carlo predictions were better calibrated which leads to output probabilities reflecting more accurately the true likelihood of being correctly classified.
翻译:将人工智能纳入临床工作流程需要可靠和稳健的模型。重复性是模型稳健性的一个关键属性。重复性模型输出预测在类似条件下进行的独立测试期间变化较少的重复性模型输出预测。在模型开发和评价期间,大量关注分类性能,而很少评估模型重复性,导致开发临床实践中无法使用的模型。在这项工作中,我们评估四种模型类型(双级分类、多级分类、交级分类和回归)对同一病人在同一访问中从同一病人获得的图像的重复性能。我们研究了在公共和私营数据集中四项医学图像分类任务的二进制、多级、交级和回归性模型的性能变化性能,这四项任务包括:膝盖骨髓炎、宫颈癌筛查、乳腺密度估计和对发育前的偏差。对ResNet和DenseNet结构的重复性进行了衡量和比较。此外,我们评估测试时对蒙特卡洛辍学预测的准确性能和可重复性的影响。我们利用蒙特卡洛的重复性预测大大提高了对硬性能的重复性性性性性,在16个标准中,通过平均的升级和升级来反映我们的标准值的升级结果。