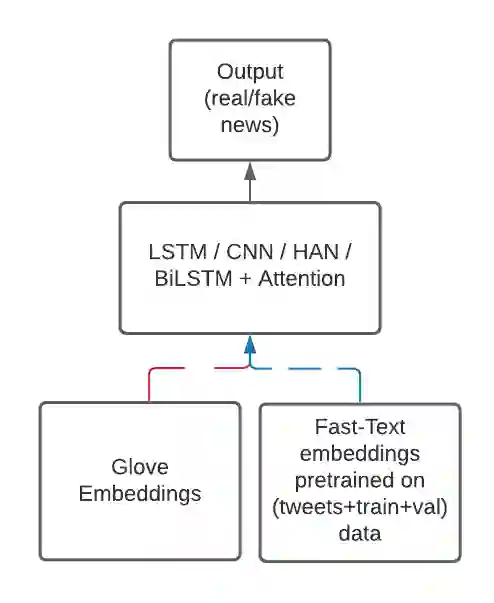
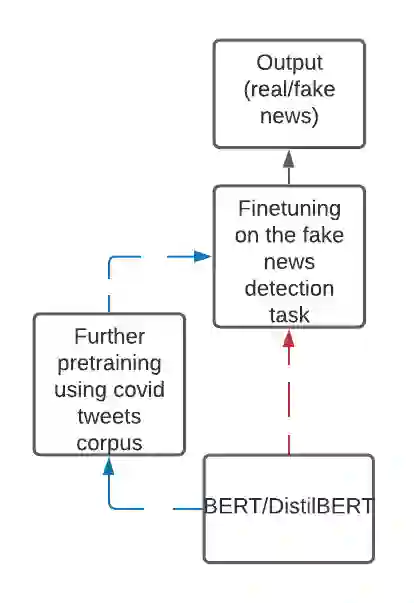
Social media platforms like Facebook, Twitter, and Instagram have enabled connection and communication on a large scale. It has revolutionized the rate at which information is shared and enhanced its reach. However, another side of the coin dictates an alarming story. These platforms have led to an increase in the creation and spread of fake news. The fake news has not only influenced people in the wrong direction but also claimed human lives. During these critical times of the Covid19 pandemic, it is easy to mislead people and make them believe in fatal information. Therefore it is important to curb fake news at source and prevent it from spreading to a larger audience. We look at automated techniques for fake news detection from a data mining perspective. We evaluate different supervised text classification algorithms on Contraint@AAAI 2021 Covid-19 Fake news detection dataset. The classification algorithms are based on Convolutional Neural Networks (CNN), Long Short Term Memory (LSTM), and Bidirectional Encoder Representations from Transformers (BERT). We also evaluate the importance of unsupervised learning in the form of language model pre-training and distributed word representations using unlabelled covid tweets corpus. We report the best accuracy of 98.41\% on the Covid-19 Fake news detection dataset.
翻译:Facebook、Twitter和Instagram等社交媒体平台使信息分享速度发生了革命性的变化,提高了信息传播范围。然而,硬币的另一面却揭示了一个令人震惊的故事。这些平台导致虚假新闻的创建和传播增加。假新闻不仅对人们产生错误的影响,而且造成人命损失。在Covid19大流行的关键时刻,很容易误导人们,让他们相信致命信息。因此,必须阻止来源的假新闻,防止其传播到更多的受众。我们从数据挖掘的角度审视假新闻探测的自动技术。我们评估了 Contraint@AAI 2021 Covid-19 Fake新闻探测数据集上的不同监管文本分类算法。分类算法基于Colvalial Neal网络(CNN)、长期记忆(LSTM)和来自变异器的双向电解码表示(BERT) 。我们还评估了在语言模型前培训中进行非超导学习的重要性,并使用不贴贴标签的C-19号邮件检测报告。