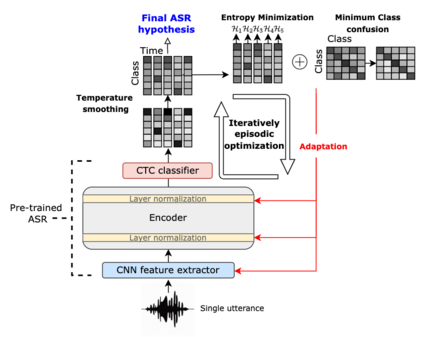
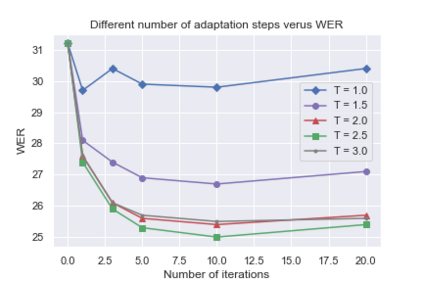
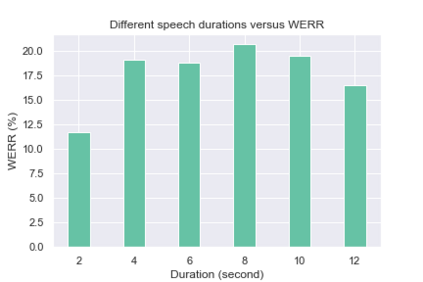
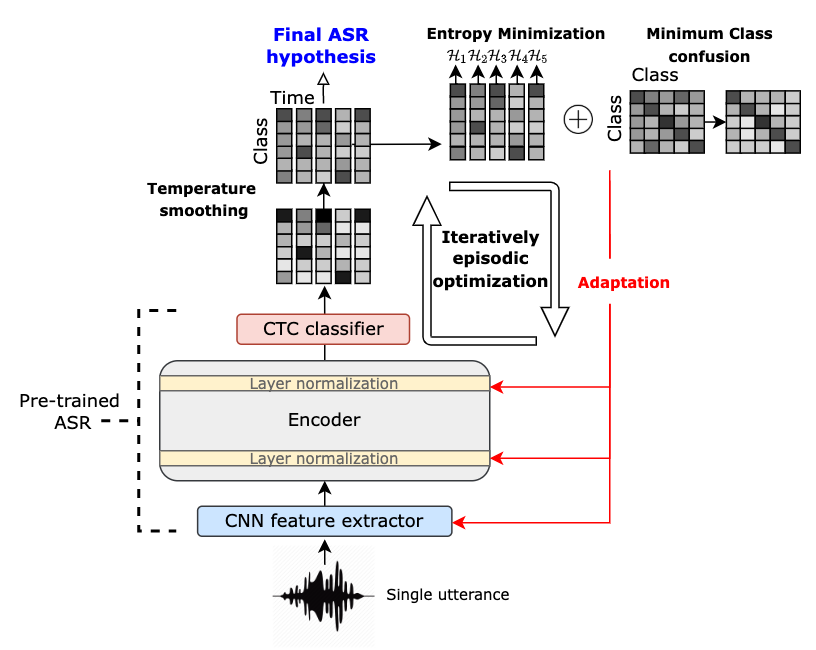
Although deep learning-based end-to-end Automatic Speech Recognition (ASR) has shown remarkable performance in recent years, it suffers severe performance regression on test samples drawn from different data distributions. Test-time Adaptation (TTA), previously explored in the computer vision area, aims to adapt the model trained on source domains to yield better predictions for test samples, often out-of-domain, without accessing the source data. Here, we propose the Single-Utterance Test-time Adaptation (SUTA) framework for ASR, which is the first TTA study on ASR to our best knowledge. The single-utterance TTA is a more realistic setting that does not assume test data are sampled from identical distribution and does not delay on-demand inference due to pre-collection for the batch of adaptation data. SUTA consists of unsupervised objectives with an efficient adaptation strategy. Empirical results demonstrate that SUTA effectively improves the performance of the source ASR model evaluated on multiple out-of-domain target corpora and in-domain test samples.
翻译:虽然近年来基于深层次学习的端到端自动语音识别(ASR)表现显著,但在从不同数据分布中提取的测试样品上却出现了严重的性能倒退,以前在计算机视野领域探索过的测试时间适应(TTA)旨在调整在源域方面受过培训的模型,以便对测试样品作出更好的预测,这些样品往往是在外部,没有访问源数据。在这里,我们建议为ASR建立单一-异常测试时间适应(SUTA)框架,这是我们最了解的关于ASR的首次TTA研究。单价TA是一种更现实的设定,它不假定测试数据是从相同的分布中取样的,不因收集成套适应数据而延迟需求推论。SUTA由不受监督的目标组成,而没有获得有效的适应战略。经验性结果表明,SUTA有效改进了在多个局外目标公司和内部测试样品上评估的源ASR模型的性能。