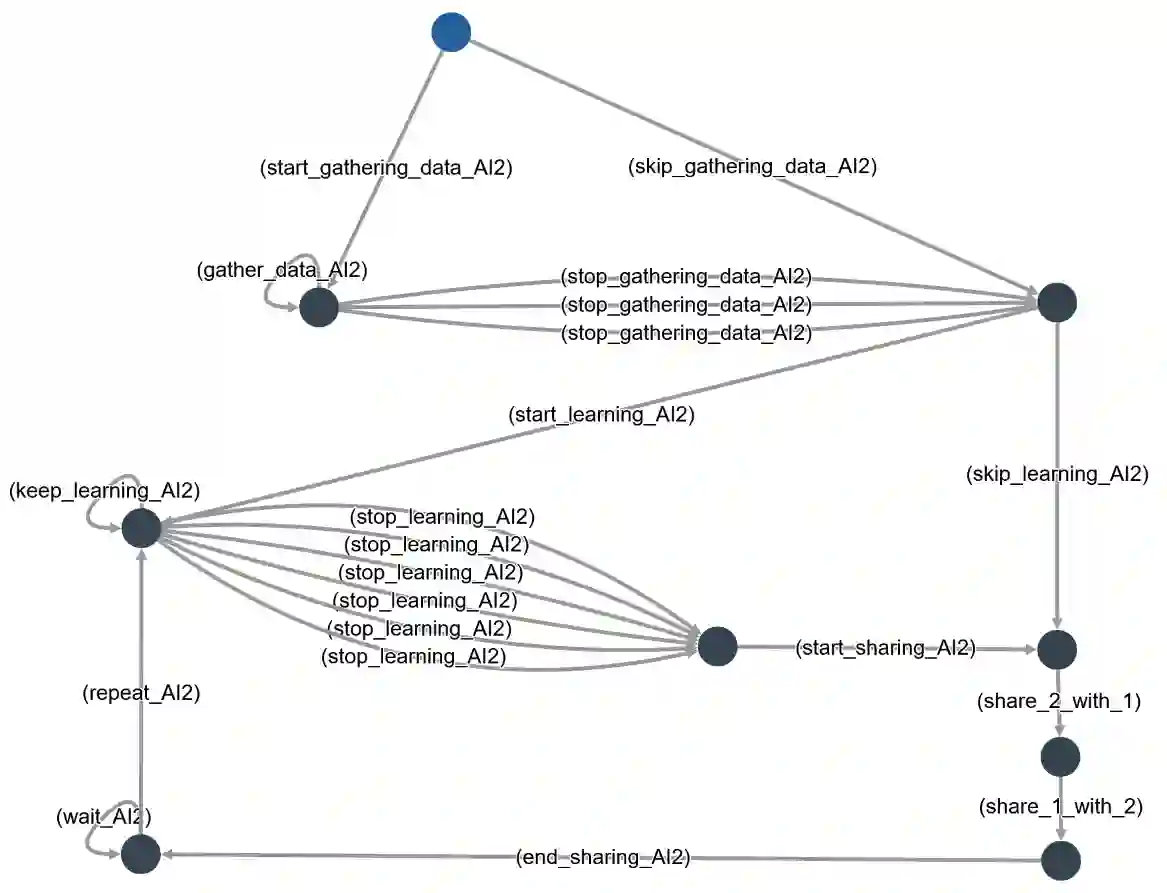
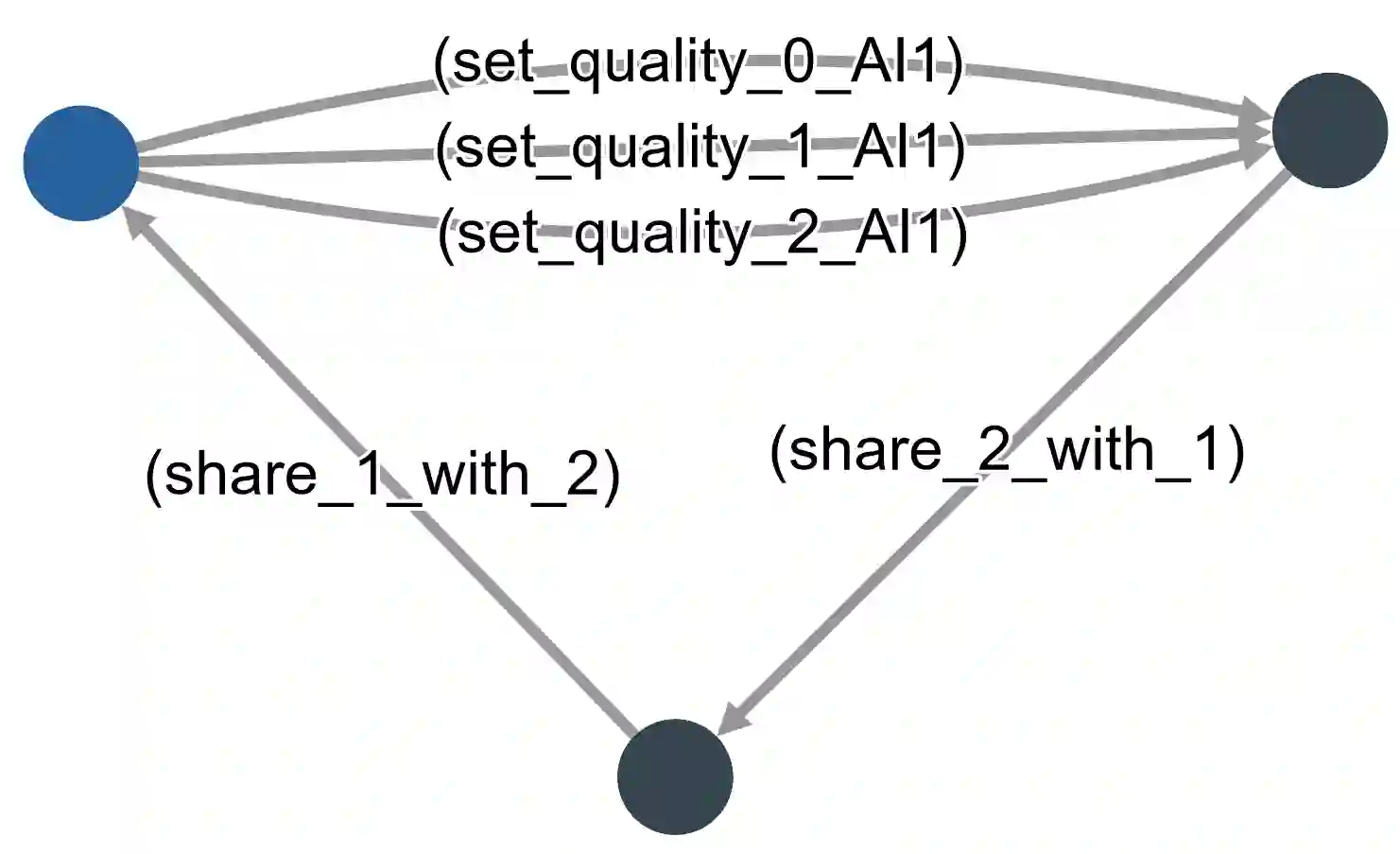
Social Explainable AI (SAI) is a new direction in artificial intelligence that emphasises decentralisation, transparency, social context, and focus on the human users. SAI research is still at an early stage. Consequently, it concentrates on delivering the intended functionalities, but largely ignores the possibility of unwelcome behaviours due to malicious or erroneous activity. We propose that, in order to capture the breadth of relevant aspects, one can use models and logics of strategic ability, that have been developed in multi-agent systems. Using the STV model checker, we take the first step towards the formal modelling and verification of SAI environments, in particular of their resistance to various types of attacks by compromised AI modules.
翻译:暂无翻译