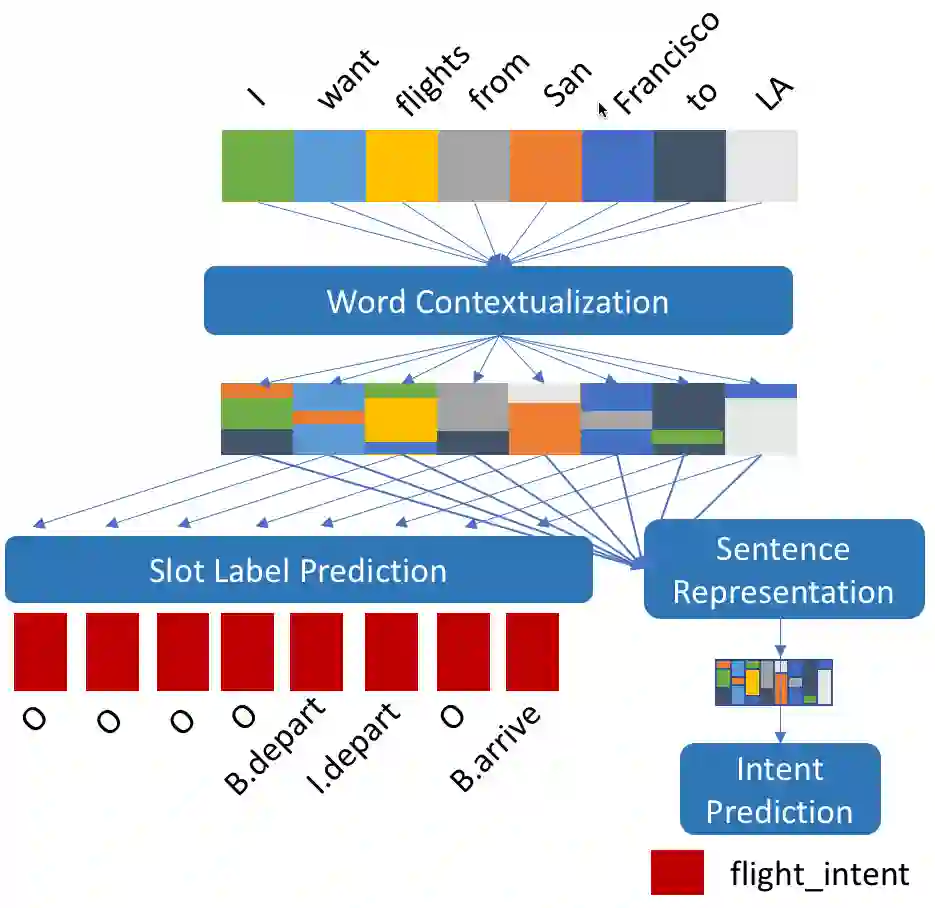
With the advent of conversational assistants, like Amazon Alexa, Google Now, etc., dialogue systems are gaining a lot of traction, especially in industrial setting. These systems typically consist of Spoken Language understanding component which, in turn, consists of two tasks - Intent Classification (IC) and Slot Labeling (SL). Generally, these two tasks are modeled together jointly to achieve best performance. However, this joint modeling adds to model obfuscation. In this work, we first design framework for a modularization of joint IC-SL task to enhance architecture transparency. Then, we explore a number of self-attention, convolutional, and recurrent models, contributing a large-scale analysis of modeling paradigms for IC+SL across two datasets. Finally, using this framework, we propose a class of 'label-recurrent' models that otherwise non-recurrent, with a 10-dimensional representation of the label history, and show that our proposed systems are easy to interpret, highly accurate (achieving over 30% error reduction in SL over the state-of-the-art on the Snips dataset), as well as fast, at 2x the inference and 2/3 to 1/2 the training time of comparable recurrent models, thus giving an edge in critical real-world systems.
翻译:随着对话助理的出现,如亚马逊亚历克萨、谷歌即时等,对话系统正在获得许多牵引力,特别是在工业环境中。这些系统通常由口语语言理解部分组成,后者又由两个任务组成:本级分类(IC)和Slot Labeling(SL)。一般而言,这两个任务是共同建模的,以取得最佳业绩。然而,这种联合建模增加了模型的模糊性。在这项工作中,我们首先设计了IC-SL联合任务模块化框架,以提高建筑透明度。然后,我们探索了一些自我自留、动态和经常性模型,对IC+SL在两个数据集中的模型模型模型进行大规模分析。最后,我们利用这个框架,提出了一组“标签-经常”模型,这些模型本来是非经常性的,对标签历史有10维的描述,并表明我们提议的系统很容易解释,非常准确(在SL上发现超过30%的误差,在Snips实时系统上提供了精确的精确度2/2和精确度的模型,从而在Snips-weral Serview pral sy system sy systemal systemmm sy systemal systelation 2/2和2/2 surview surviews-view surview symal syxxxxxx survild surviews sy sy sy sy sy sy sy syx symal symm syx syxx symstrvil) 和在精确的系统提供了。