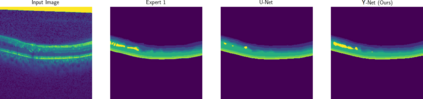
Automated segmentation of retinal optical coherence tomography (OCT) images has become an important recent direction in machine learning for medical applications. We hypothesize that the anatomic structure of layers and their high-frequency variation in OCT images make retinal OCT a fitting choice for extracting spectral-domain features and combining them with spatial domain features. In this work, we present $\Upsilon$-Net, an architecture that combines the frequency domain features with the image domain to improve the segmentation performance of OCT images. The results of this work demonstrate that the introduction of two branches, one for spectral and one for spatial domain features, brings a very significant improvement in fluid segmentation performance and allows outperformance as compared to the well-known U-Net model. Our improvement was 13% on the fluid segmentation dice score and 1.9% on the average dice score. Finally, removing selected frequency ranges in the spectral domain demonstrates the impact of these features on the fluid segmentation outperformance.
翻译:视网膜光学一致性断层成像(OCT)图像的自动分离已成为医学应用机器学习中最近的一个重要方向。我们假设,层层的解剖结构及其在OCT图像中的高频变异使视网膜OCT成为提取光谱域特征并将其与空间域特征结合的合适选择。在这项工作中,我们展示了$\Upsilon$-Net,这是一个将频率域特征与图像域结合的架构,以改善OCT图像的分离性能。这项工作的结果表明,引入两个分支,一个是光谱分支,一个是空间域特征,极大地改进了液分层性能,并使得与众所周知的U-Net模型相比,性能优于人性。我们的改进是:液分 dice分分位的13%,和平均 dice分分数的1.9%。最后,删除光谱域中选定的频域的频域显示了这些特征对液分差性效果的影响。