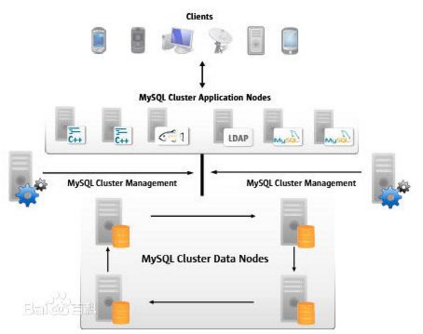
Big Data is considered proprietary asset of companies, organizations, and even nations. Turning big data into real treasure requires the support of big data systems. A variety of commercial and open source products have been unleashed for big data storage and processing. While big data users are facing the choice of which system best suits their needs, big data system developers are facing the question of how to evaluate their systems with regard to general big data processing needs. System benchmarking is the classic way of meeting the above demands. However, existent big data benchmarks either fail to represent the variety of big data processing requirements, or target only one specific platform, e.g. Hadoop. In this paper, with our industrial partners, we present BigOP, an end-to-end system benchmarking framework, featuring the abstraction of representative Operation sets, workload Patterns, and prescribed tests. BigOP is part of an open-source big data benchmarking project, BigDataBench. BigOP's abstraction model not only guides the development of BigDataBench, but also enables automatic generation of tests with comprehensive workloads. We illustrate the feasibility of BigOP by implementing an automatic test generation tool and benchmarking against three widely used big data processing systems, i.e. Hadoop, Spark and MySQL Cluster. Three tests targeting three different application scenarios are prescribed. The tests involve relational data, text data and graph data, as well as all operations and workload patterns. We report results following test specifications.
翻译:将大数据转换成真正的宝藏需要大数据系统的支持。 各种商业和开放源码产品已经为大数据存储和处理而推出。 虽然大数据用户正面临选择哪个系统最适合其需要,但大数据系统开发者正面临如何根据一般大数据处理需求评价其系统的问题。 系统基准是满足上述需求的典型方法。 然而,现有的大数据基准要么不能代表大数据处理要求的多样性,要么只针对一个特定平台,例如哈道普。在本文件中,我们与我们的工业伙伴一起介绍了BigOP,一个端对端系统基准框架,其特点是具有代表性的成套业务、工作量模式和规定的测试。大数据系统是开源大数据基准项目BigDataBechnch. BigOP的抽象模型的一部分,它不仅指导BigDataBench的开发,而且能够自动生成具有全面工作量的测试。我们通过实施自动测试生成工具的可行性,并对照三种广泛使用的数据规格进行基准测试。